




Pubblicato il - Aggiornato il
Crawling SEO: cos’è la scansione di un sito e come ottimizzarla

Quando gestisci un ecommerce o un sito molto strutturato, il problema non è “se” Googlebot ti trova: è quanto spesso scansiona le pagine giuste e quanta energia spreca su filtri, parametri, duplicati e URL inutili. Capire il crawling in modo data-driven significa leggere i segnali reali (log, header, status code) e incrociarli con ciò che vedi in Search Console, per misurare dove stai bruciando crawl budget e dove invece stai rallentando indicizzazione e performance.
L’obiettivo qui è trasformare l’analisi in priorità operative chiare: cosa correggere prima, chi coinvolgere nel team/fornitori e quali KPI usare per validare l’impatto. Partiamo dalle basi, distinguendo bene crawling, indicizzazione e ranking, così da intervenire con metodo e risultati misurabili.
Indice dei contenuti
Crawling, indicizzazione e ranking: differenze che cambiano le priorità
Nel lavoro quotidiano su siti grandi è facile usare questi tre termini come sinonimi, ma in realtà descrivono fasi diverse e, soprattutto, richiedono fix diversi. Se confondi i livelli, rischi di “ottimizzare” la cosa sbagliata (magari il contenuto) mentre il problema reale è a monte (scansione) o a valle (indicizzazione). Qui la regola pratica è: prima fai arrivare Google sulle pagine giuste, poi fai sì che le consideri indicizzabili, infine lavora per farle competere.

Crawling: come Googlebot scopre e visita gli URL
Il crawling è la fase in cui Googlebot scopre gli URL (tramite link interni/esterni e sitemap) e li richiede al server. In questa fase contano tantissimo i segnali “meccanici”: struttura dei link, risposta del server, status code, tempo di risposta e quantità di URL disponibili da esplorare. Su ecommerce con categorie, filtri e varianti, il punto non è avere “tante pagine”, ma avere troppe versioni della stessa pagina.
Un aspetto spesso sottovalutato è che la scansione non è solo “visitare l’HTML”. Se una pagina richiede rendering pesante (JavaScript, risorse bloccate, chiamate lente), il costo di scansione sale e la copertura può peggiorare. In pratica: più la pagina è complessa da recuperare, più è probabile che il bot riduca la frequenza o distribuisca male le richieste, soprattutto su siti molto estesi.
Da qui nasce la prima priorità operativa: ridurre la superficie di URL inutili e rendere immediata la scoperta di quelli che contano (categorie strategiche, prodotti in stock, contenuti evergreen). Se questa base non è solida, tutto il resto (ottimizzazioni di contenuto incluse) tende ad avere un impatto più lento e meno prevedibile.
Indicizzazione: cosa finisce nell’indice (e cosa resta fuori)
L’indicizzazione è la fase in cui Google decide se salvare (e come salvare) una pagina nel proprio indice. Qui entrano in gioco segnali come canonical, noindex, duplicazione, qualità e unicità del contenuto, ma anche aspetti tecnici: pagine che rispondono 200 ma hanno contenuto “scarso” o incoerente possono essere scansionate e comunque restare fuori.
In Search Console questa dinamica si vede bene nel report “Pagine”: URL “Scoperta, attualmente non indicizzata” o “Scansionata, attualmente non indicizzata” spesso indicano che Google conosce la pagina ma non la considera prioritaria o abbastanza valida da tenere in indice. Su siti grandi, questi stati possono diventare il sintomo di un problema strutturale: troppe URL simili, troppe varianti, segnali di canonicalizzazione confusi.
La differenza chiave è questa: puoi far scansionare una pagina, ma non puoi “forzare” l’indicizzazione se i segnali dicono a Google che è ridondante o poco utile. Per questo l’ottimizzazione del crawling va sempre letta insieme alla qualità dell’informazione e al controllo dei duplicati.
Ranking: come la pagina compete nei risultati
Il ranking è la fase in cui, a parità di indicizzazione, Google decide dove posizionare una pagina per una query specifica. È il livello più “visibile” perché impatta direttamente traffico e vendite, ma dipende dai due livelli precedenti: una pagina non scansionata o non indicizzata non può competere davvero.
C’è anche un aspetto “di freschezza” spesso trascurato: se Googlebot scansiona raramente le pagine importanti, gli aggiornamenti (prezzo, disponibilità, contenuti) possono arrivare tardi nei risultati. Questo si traduce in un problema di performance organica e, nel caso degli ecommerce, anche di esperienza utente: atterraggi su pagine non aggiornate e conversioni che ne risentono.
Ottimizzare la scansione, quindi, non è un esercizio tecnico fine a sé stesso: significa far sì che Google veda spesso ciò che vuoi spingere e molto meno ciò che non vuoi far “consumare” al bot. E questo crea un contesto più stabile per le attività di contenuto e di CRO.
Crawl budget: quando diventa un problema (e quando no)
Il crawl budget non è una metrica “magica”, ma un concetto utile per ragionare su come Google distribuisce le proprie risorse sul tuo sito. La buona notizia: per molti siti piccoli non è un limite reale. La cattiva notizia: su ecommerce e portali con migliaia (o milioni) di URL, può diventare un collo di bottiglia concreto, soprattutto se il sito genera continuamente nuove varianti di pagine.
Da cosa dipende il crawl budget: domanda vs capacità
In modo semplificato, il crawl budget nasce dall’equilibrio tra domanda di scansione (quanto Google “vuole” scansionare il sito) e capacità di scansione (quanto il server “può” reggere senza degradare). La domanda cresce se il sito è popolare, aggiornato spesso e con pagine che cambiano di frequente; cala se Google percepisce tante URL poco utili o ridondanti.
La capacità, invece, è molto legata alla salute tecnica: se aumentano errori 5xx, timeout o tempi di risposta, Googlebot tende a rallentare per non stressare il server. Qui entra in gioco anche la qualità dell’infrastruttura: caching, CDN, ottimizzazione del TTFB e gestione dei picchi. Un sito veloce e stabile “invita” scansioni più efficienti.
Su siti grandi, questo equilibrio si rompe facilmente: basta una migrazione, una nuova logica di filtri o un problema lato server per far spostare Googlebot su un comportamento difensivo. E quando succede, spesso lo noti dopo settimane (perché si accumula ritardo tra nuove pagine pubblicate e pagine realmente viste/aggiornate nei risultati).
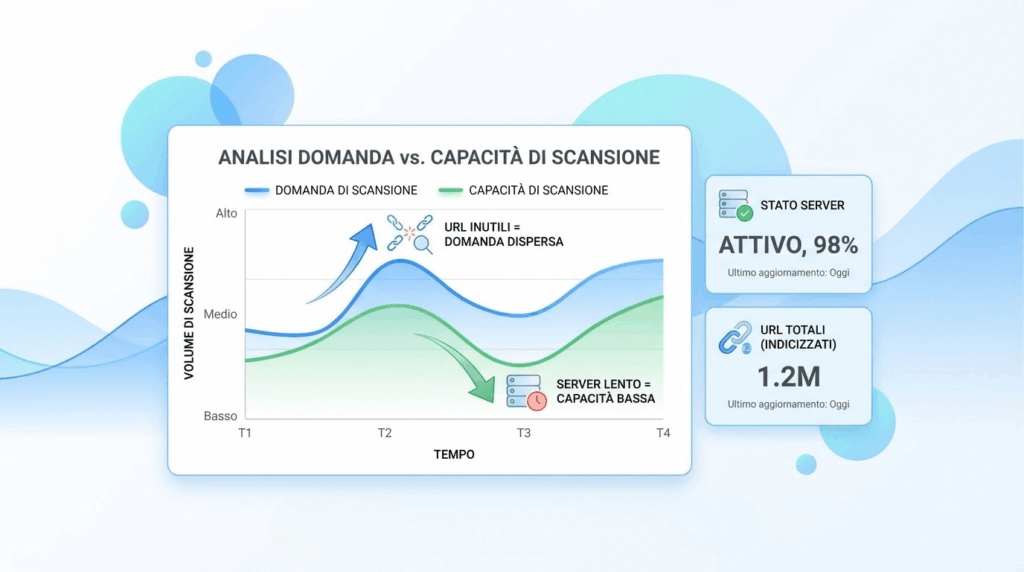
Sprechi tipici su ecommerce e siti con filtri
Lo spreco più comune è la creazione di “spazi infiniti” di URL: filtri combinabili, ordinamenti, parametri di tracciamento, pagine di ricerca interna, paginazioni profonde. Anche se molte di queste URL non dovrebbero essere indicizzate, possono comunque essere scansionate a lungo, drenando risorse dalle pagine che contano davvero.
In pratica, Googlebot finisce per distribuire la scansione su: pagine duplicate con parametri diversi, versioni quasi identiche della stessa categoria, URL con ordinamenti differenti, combinazioni di filtri che generano contenuti troppo simili. Se in più i link interni “spingono” queste varianti (menu, facet, breadcrumb, moduli), la scoperta accelera e lo spreco diventa sistemico.
Qui la strategia non è “bloccare tutto”: è decidere quali template e quali combinazioni hanno valore SEO e quali no, e far sì che i segnali siano coerenti (internal linking, canonical, noindex, sitemap). Quando i segnali sono ambigui, Google può comunque spendere crawl budget per “capire” cosa fare, e spesso lo fa nel modo meno conveniente per te.
Segnali pratici che indicano un limite di crawling
Il segnale più chiaro, lato business, è vedere nuove pagine importanti che impiegano troppo tempo a comparire o aggiornarsi in SERP. A volte il problema non è “non indicizzate”, ma “non rinfrescate”: Google le conosce, ma le visita troppo raramente rispetto a quanto cambiano.
Dal punto di vista data-driven, incrocia “Statistiche di scansione” in Search Console con i log: se vedi tante richieste su URL con parametri e poche richieste su directory strategiche (categorie/prodotti), hai un problema di allocazione. Se vedi crescere la quota di 3xx/4xx/5xx, stai bruciando budget su errori e redirect.
La parte importante è non lavorare a sensazione: definisci una baseline (es. quota di scan su URL “indexable e canoniche”, tempo medio di risposta, errori) e poi misura l’effetto dei fix. È l’unico modo per trasformare l’ottimizzazione del crawling in un’attività con priorità chiare e risultati verificabili.
Misurare il crawling con i dati: Search Console + log analysis
Se gestisci un sito strutturato, l’analisi del crawling va fatta “a due lenti”. Search Console ti dà un’ottima vista aggregata e comparabile nel tempo; i log ti dicono cosa è successo davvero, URL per URL. La combinazione delle due fonti è ciò che permette di prendere decisioni solide e spiegabili anche a team e fornitori.
Statistiche di scansione in Google Search Console: cosa guardare davvero
Nel report “Statistiche di scansione” puoi leggere trend utili: numero di richieste, dimensione scaricata e tempi di risposta. Il valore non è la “quantità assoluta” (che varia molto tra siti), ma le variazioni: picchi, cali, cambiamenti di mix tra risposte 200/3xx/4xx/5xx e aumento dei tempi di risposta.
Quando vedi un peggioramento, la domanda giusta non è “Google ci penalizza?”, ma “cosa è cambiato sul sito o sul server?”. Deploy, nuove regole di redirect, filtri aggiunti, performance degradate: quasi sempre la causa è interna e rintracciabile. Search Console, in questo senso, è un sistema di early warning più che un tool di diagnosi di dettaglio.
Se vuoi portare l’analisi su un livello operativo (e farla diventare routine), ha senso esportare i dati e metterli in dashboard, così da annotare eventi (rilasci, migrazioni, campagne) e correlare le oscillazioni del crawling con azioni concrete. In scenari complessi, questo riduce molto il classico ping-pong tra marketing, SEO e IT.
Analisi dei log: l’unico modo per vedere cosa fanno i bot sul serio
I log del server sono la fonte più affidabile perché registrano ogni richiesta: chi l’ha fatta, quando, su quale URL e con quale esito. È qui che smetti di ragionare per ipotesi e inizi a misurare davvero la scansione del sito web: quali sezioni ricevono attenzione, quali URL “inutili” assorbono richieste, dove si concentrano errori e redirect.
Per lavorarci bene serve un minimo di governance: accesso ai log (o esport periodici), verifica dei bot (non tutti gli user-agent sono “Googlebot” reale) e una segmentazione sensata (per directory, template, parametri, tipologia pagina). Su ecommerce, questa segmentazione è spesso la chiave: ti permette di dire “il 40% delle richieste va su URL con parametri di filtro” invece di restare su numeri generici.
Nell’estrazione dati, ci sono alcuni campi/metriche che diventano subito azionabili per ottimizzare il crawl budget:
- URL richiesto (con e senza parametri)
- User-agent e IP (per validare Googlebot)
- Status code (200, 3xx, 4xx, 5xx)
- Timestamp (per frequenza e pattern nel tempo)
- Tempo di risposta (o latenza lato server)
- Byte trasferiti (per peso medio delle risposte)
Una volta che li hai, puoi costruire insight molto pratici: “Googlebot visita spesso URL non canoniche”, “ci sono catene di redirect su pagine di categoria”, “le pagine prodotto lente vengono scansionate meno”. E da lì passi direttamente a ticket tecnici con evidenze, non opinioni.
Dashboard e priorità: unire crawling e performance in una vista unica
Il salto di qualità arriva quando colleghi i dati di crawling a ciò che conta per il business. Una dashboard in Looker Studio (o un report condiviso) può unire: log + Search Console + informazioni di template (categorie/prodotti) + segnali di valore (impression/click organici, pagine che generano revenue, contenuti strategici). Così puoi vedere non solo “cosa scansiona Google”, ma “cosa scansiona rispetto al valore”.
Una vista utile, soprattutto per coordinare più team, è quella per directory/template: quante richieste su /categoria/, quante su /prodotto/, quante su URL con parametri, quante su pagine 404. Se aggiungi il tempo di risposta medio e la quota di errori, ottieni una mappa chiara di dove intervenire prima per sbloccare copertura e ridurre sprechi.
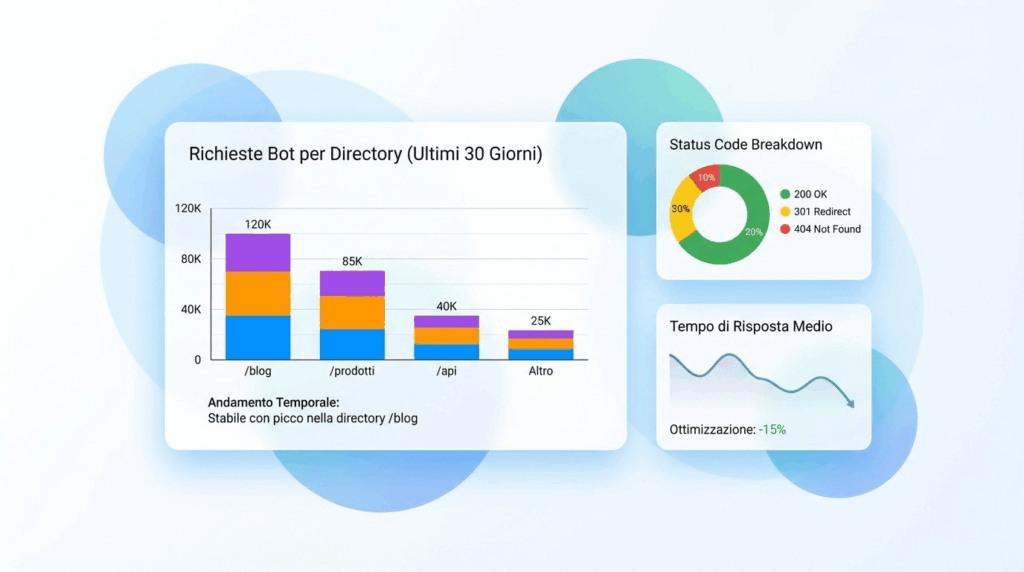
Con questa impostazione, la conversazione cambia: non è più “sistemiamo i bot”, ma “riduciamo del X% le richieste su URL inutili e aumentiamo la scansione sulle pagine che portano traffico e conversioni”. È più facile ottenere risorse e fare iterazione, perché stai parlando per KPI.
Problemi tecnici che bloccano la scansione (o la rendono inefficiente)
Molti siti non hanno un “problema di crawling” unico, ma una somma di piccoli attriti tecnici che, su larga scala, diventano enormi. L’obiettivo non è azzerare ogni anomalia, ma eliminare quelle che spostano davvero la distribuzione delle scansioni o impediscono a Google di leggere correttamente le pagine importanti.
Status code e redirect: 3xx, 4xx, 5xx che rubano crawl budget
I redirect 3xx sono normali, ma diventano un problema quando sono in catena (A→B→C) o, peggio, in loop. Ogni salto è una richiesta in più e, su siti grandi, si traduce in migliaia di richieste “sprecate” al giorno. Inoltre, catene e loop complicano i segnali di canonicalizzazione e rallentano la scoperta della destinazione finale.
I 4xx sono un’altra fonte di spreco tipica negli ecommerce: prodotti rimossi, categorie rinominate, URL generate da filtri che poi spariscono. Se l’internal linking continua a puntare a URL non valide, Googlebot continuerà a provarci. Qui spesso la fix non è solo “fare redirect”, ma ripulire link interni e regole che generano URL errate.
Gli errori 5xx (o timeout) sono ancora più impattanti perché toccano la capacità di scansione: se il server è instabile, Google rallenta. In questi casi la priorità diventa tecnica e immediata: stabilità, caching, riduzione del tempo di risposta e monitoraggio, perché un miglioramento lato server può aumentare la copertura molto più di qualunque micro-ottimizzazione SEO.
Robots.txt, meta robots e X-Robots-Tag: governare cosa può essere scansionato
Qui serve chiarezza: robots.txt controlla la scansione, mentre i meta tag robots (es. noindex) controllano l’indicizzazione, ma per leggere un noindex Google deve poter scansionare la pagina. Se blocchi una directory via robots.txt e poi ti aspetti che Google “veda” il noindex o il canonical, stai inviando segnali contraddittori.
Errore frequente: bloccare risorse utili (CSS/JS) e rendere più difficile il rendering, oppure ereditare regole da ambienti di staging che finiscono in produzione. Su siti grandi, queste regressioni succedono: per questo è utile trattare robots.txt come un file “di progetto”, con controllo versione e review tecnica.
Per file non HTML (PDF, feed, asset) può entrare in gioco l’X-Robots-Tag, che permette di impostare noindex a livello di header HTTP. È una leva potente, ma va governata: prima di applicarla su larga scala, valida sempre su un campione e misura l’effetto nei log e in Search Console.
Canonical, duplicati e navigazione a faccette: ridurre la superficie di URL
Il tag canonical è uno dei principali strumenti per dire a Google qual è la versione “preferita” di un contenuto, soprattutto quando esistono molte varianti di URL. Ma funziona bene solo se i segnali attorno sono coerenti: link interni che puntano alla canonica, sitemap pulite, assenza di contraddizioni (tipo canonica verso A ma internal link che spinge B).
La navigazione a faccette (filtri) è il terreno più delicato: alcune combinazioni hanno valore SEO (e vanno rese indicizzabili), altre vanno trattate come varianti tecniche. In quel caso la scelta è architetturale: riduci le combinazioni esposte, controlla l’indexabilità e fai in modo che Google trovi facilmente le pagine “hub” che vuoi far posizionare.
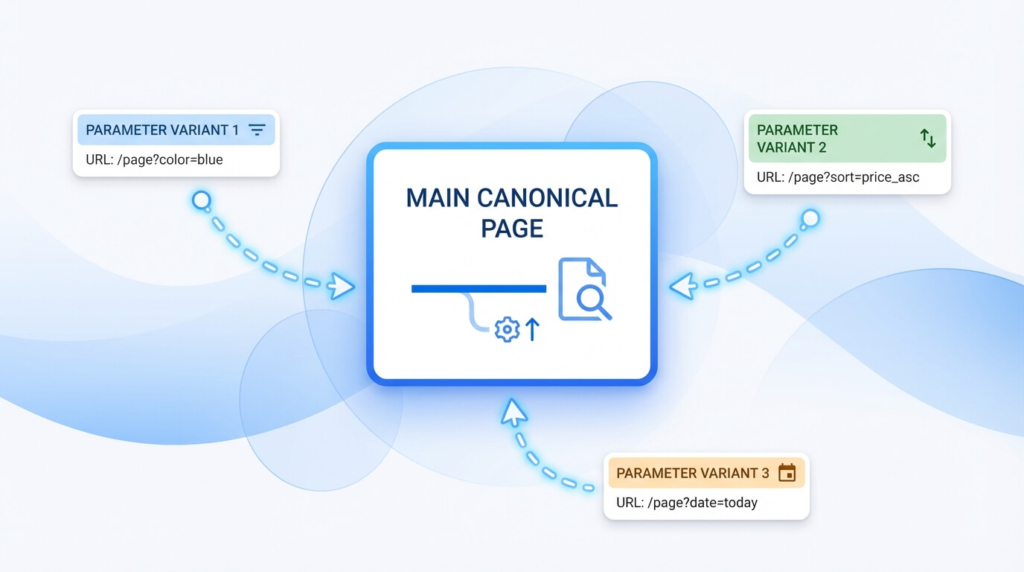
Un buon indicatore di salute è vedere coerenza tra: URL in sitemap, URL linkate internamente e URL che ricevono scansioni nei log. Quando queste tre liste non “si parlano”, quasi sempre stai alimentando duplicati e sprechi.
Come far scoprire e (ri)scansionare le pagine importanti
Ottimizzare il crawling non significa solo togliere ostacoli, ma anche facilitare la scoperta e la riscoperta dei contenuti che contano. Su siti con molte pagine, Google non può (e non vuole) controllare tutto ogni giorno: devi aiutarlo a capire cosa è importante e cosa è cambiato davvero.
Sitemap XML in Search Console: struttura, segmentazione e controllo degli errori
La sitemap XML è uno dei canali più puliti per indicare a Google quali URL vuoi far scoprire e mantenere sotto controllo. Il punto chiave è la qualità: una sitemap piena di URL non canoniche, redirect o pagine bloccate genera rumore e indebolisce il segnale complessivo.
Su ecommerce è spesso utile segmentare: sitemap per categorie, prodotti, contenuti editoriali, e un sitemap index che le raccoglie. Questo rende più semplice diagnosticare problemi (es. “i prodotti nuovi non vengono letti”) e consente anche una gestione più sostenibile con team e fornitori, perché ogni area ha responsabilità e controlli più chiari.
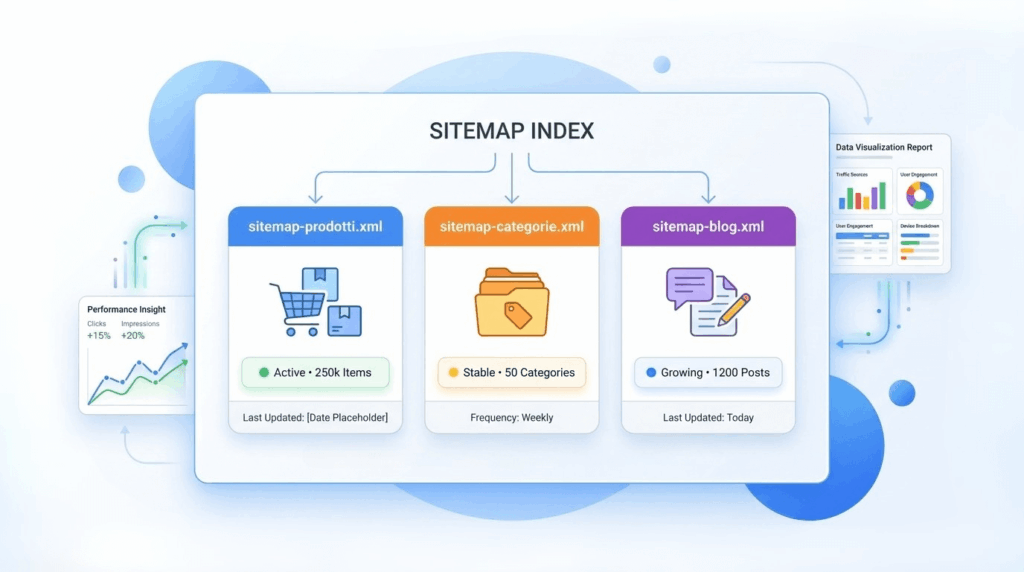
In Search Console, controlla regolarmente lo stato di invio/lettura e gli eventuali errori. Non è un check “una tantum”: è un punto di monitoraggio continuo, soprattutto dopo rilasci, migrazioni o cambi di regole sui parametri.
Controllo URL e “Richiedi indicizzazione”: quando usarlo e limiti reali
Lo strumento Controllo URL è perfetto per lavorare in modo chirurgico: verificare lo stato di un singolo URL, vedere la canonica scelta da Google, controllare se ci sono blocchi e fare un test live. È anche utile dopo un fix tecnico (redirect, robots, canonical) per validare che l’implementazione sia corretta prima di estenderla.
La funzione “Richiedi indicizzazione” va usata con aspettative realistiche: non è un bottone per indicizzare migliaia di pagine e non sostituisce una strategia di crawling. Ha senso su URL critici (nuove categorie, pagine ad alto valore, contenuti aggiornati) o quando devi accelerare la rivalutazione dopo un bug risolto.
Il modo più efficace di usarlo, in ottica operativa, è questo: campiona, valida, scala. Prima controlli un set rappresentativo di URL, poi applichi la correzione su larga scala, infine misuri l’effetto nei log e nei report di Search Console.
Lastmod, frequenza di aggiornamento e segnali di aggiornamento reale
Il campo lastmod in sitemap può aiutare Google a capire quali URL sono cambiati, ma solo se è affidabile. Se aggiorni lastmod ogni giorno “a prescindere”, stai segnalando cambiamenti che non esistono: alla lunga è un segnale che perde valore e può aumentare scansioni poco utili.
Su ecommerce, una buona pratica è legare lastmod a cambiamenti reali: disponibilità, prezzo, descrizione, varianti, contenuti multimediali, informazioni di spedizione. Se il CMS lo consente, è meglio calcolarlo su eventi concreti invece che su timestamp generici di pubblicazione o rebuild.
Oltre a lastmod, puoi rafforzare i segnali con header HTTP come Last-Modified o ETag e, soprattutto, con internal linking intelligente: quando una categoria cambia davvero (nuovi prodotti, nuove priorità), farla linkare da sezioni ad alta frequenza di scansione accelera spesso la riscoperta. La validazione, come sempre, è nei dati: guarda nei log quanto tempo passa tra aggiornamento e nuova visita di Googlebot, e verifica se le pagine “fresche” stanno ricevendo più attenzione rispetto al passato.
Piano di ottimizzazione del crawling: dalla diagnosi alle implementazioni
Su siti complessi, l’ottimizzazione del crawling è un progetto, non un intervento singolo. La parte che fa davvero la differenza è trasformare l’analisi in un backlog ordinato, con responsabilità chiare e KPI condivisi. Se resta “un audit”, non diventa mai performance misurabile.
Prioritizzare con impatto e sforzo: backlog condiviso tra marketing, SEO e IT
Per evitare di disperdersi, conviene separare: problemi bloccanti (che impediscono scansione/indicizzazione), problemi di spreco (che drenano risorse), miglioramenti incrementali (che aumentano efficienza nel tempo). Questo aiuta a negoziare priorità con l’IT e con eventuali fornitori, perché ogni ticket è legato a un impatto misurabile.
Quando apri task tecnici sul crawling, porta sempre evidenze: estratti di log, screenshot di Search Console, esempi di URL e pattern ripetibili. È molto più efficace di una richiesta generica tipo “Google non scansiona bene”. Inoltre, definisci criteri di accettazione chiari: cosa deve cambiare (es. riduzione catene di redirect), dove lo misuri e in che finestra temporale.
Questo approccio rende sostenibile l’iterazione: rilasci piccoli ma frequenti, misurazione, aggiustamenti. È esattamente il tipo di processo che regge nel tempo su siti con tante pagine e cambi continui.
KPI per validare i fix: cosa misurare prima e dopo
Senza KPI, l’ottimizzazione del crawling rischia di diventare un’attività invisibile. Prima di toccare qualcosa, definisci una baseline: distribuzione delle richieste nei log (per directory e pattern), quota di status code problematici, tempo di risposta, rapporto tra URL scansionate e URL realmente importanti (canoniche e indexabili).
Dopo i fix, misura due livelli. Il primo è tecnico: riduzione di 404/5xx, meno catene 3xx, tempi di risposta migliori e aumento della quota di scansione sulle sezioni strategiche. Il secondo è SEO: miglioramenti nei report di indicizzazione, riduzione di URL “escluse” per duplicazione non desiderata e tempi più rapidi di aggiornamento/nuova scoperta.
Infine collega, dove ha senso, i risultati ai KPI di marketing: impression e clic organici sulle pagine coinvolte e, per ecommerce, segnali di conversione e revenue in GA4 (con annotazioni sui rilasci per non confondere l’effetto con stagionalità o campagne). Non promette miracoli, ma dà un metodo: fai una modifica, misuri l’impatto, decidi il passo successivo.
Automazioni e alert: prevenire regressioni su siti grandi
Il crawling è “dinamico”: basta un deploy per cambiare internal linking, generare nuove URL o introdurre errori. Per questo, oltre all’audit iniziale, serve un minimo di automazione: import periodico dei log, controlli su status code, monitoraggio dei tempi di risposta e alert su anomalie.
Un setup efficace (anche semplice) combina: soglie su 5xx/timeout, variazioni improvvise nelle richieste di Googlebot per directory e controllo degli errori sitemap in Search Console. Se hai già una pipeline dati, spingere tutto in un database (es. BigQuery) e visualizzare in Looker Studio rende questi controlli accessibili anche a chi non è tecnico.
L’obiettivo non è “controllare tutto”, ma intercettare velocemente i problemi che spostano davvero il comportamento di scansione o impattano le pagine che portano valore. Se intercetti subito un aumento di 5xx, una crescita anomala di URL con parametri o un calo improvviso di richieste su una directory strategica, puoi intervenire quando il danno è ancora piccolo (e non quando hai già settimane di ritardo su indicizzazione e aggiornamenti).
Un’altra automazione utile, soprattutto su ecommerce e portali in continuo movimento, è tracciare i “nuovi pattern” che iniziano a comparire nei log: basta una modifica ai filtri o un bug sul routing per generare migliaia di URL inedite e mettere Googlebot in modalità “esplorazione infinita”. Lato SEO, questo si traduce quasi sempre in spreco di crawl budget e rallentamenti su ciò che conta.
Infine, considera che il monitoraggio non è solo per “stare tranquilli”: è una leva di governance. Con alert e dashboard condivise, marketing, SEO e IT parlano la stessa lingua (dati e impatto), riducendo tempi di diagnosi e discussioni basate su sensazioni.
Come funziona il crawling dei motori di ricerca (Google)
Capire il modello operativo di Googlebot ti aiuta a fare scelte più pulite su sitemap, link interni, JS e performance. Non serve conoscere ogni dettaglio interno di Google, ma serve avere chiaro cosa succede tra “scopro un URL”, “lo richiedo”, “lo renderizzo” e “decido se indicizzarlo”. È proprio in questi passaggi che nascono la maggior parte dei problemi di scansione sito web.
Googlebot e crawler di Google: user-agent e comportamento di scansione
Google usa diversi user-agent per scopi differenti, e nei log questo si vede chiaramente. Il più comune per la SEO è Googlebot “smartphone”, perché Google indicizza in ottica mobile-first: quindi, se la versione mobile del sito è lenta, incompleta o bloccata, stai complicando sia la scansione sia la valutazione della pagina.
In pratica, il user-agent ti serve per due cose operative: segmentare correttamente l’analisi dei log (non tutti i bot sono uguali) e verificare che le risposte del server siano coerenti per Googlebot. Alcune configurazioni (WAF, CDN, regole anti-bot) possono trattare Googlebot come traffico sospetto e introdurre 429, challenge o risposte diverse rispetto a un utente normale: sono casi subdoli perché “il sito funziona” per chi naviga, ma si degrada per il crawler.
Quando lavori sui log, ricordati che lo user-agent da solo non basta per “fidarsi”: esistono falsi Googlebot. Se devi fare analisi e decisioni importanti, valida le richieste con verifiche tecniche (reverse DNS / IP) e lavora su campioni di dati sufficientemente ampi da evitare conclusioni basate su rumore.
Come vengono scoperte le URL: link interni, link esterni e sitemap XML
Google scopre URL principalmente dai link: interni (navigazione, categorie, breadcrumb, moduli) ed esterni (citazioni e backlink). La sitemap XML è un acceleratore di discovery, ma non sostituisce l’architettura: se una pagina è in sitemap ma non riceve link interni significativi, spesso resta “conosciuta” ma poco prioritaria.
Qui entra in gioco una distinzione utile: “essere scopribile” non significa “essere importante”. Le URL scoperte tramite link forti (da pagine già visitate spesso) tendono a entrare in coda prima e a essere riesplorate più regolarmente. È uno dei motivi per cui, su siti grandi, il linking interno è una leva di crawling prima ancora che di ranking.
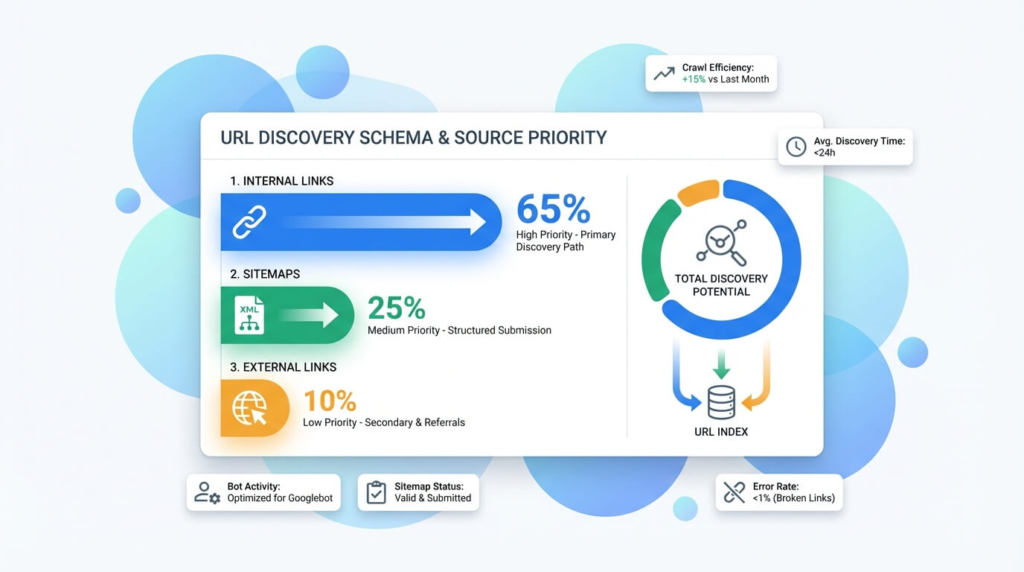
Un errore tipico è “spingere” in modo inconsapevole URL inutili: filtri linkati nel DOM, ordinamenti sempre presenti, paginazioni infinite esposte come crawlable. Se queste URL diventano parte del grafo interno, Googlebot le tratterà come contenuti da esplorare, drenando attenzione dalle pagine che generano traffico e conversioni.
Crawling e rendering: HTML, risorse bloccate e JavaScript SEO
Per molte pagine, Googlebot scarica l’HTML e riesce a estrarre contenuto e link senza problemi. Ma quando la pagina dipende in modo forte da JavaScript, entra in gioco il rendering: una fase aggiuntiva che può essere più lenta, più costosa e più fragile (risorse bloccate, chiamate lente, errori lato client).
Dal punto di vista operativo, il messaggio è semplice: se vuoi crawling efficiente, fai in modo che l’HTML iniziale contenga già i segnali chiave (titoli, testo base, link fondamentali) e che CSS/JS essenziali non siano bloccati. In molti contesti, scelte come SSR, pre-rendering o anche una riduzione delle dipendenze JS sulle pagine strategiche portano benefici misurabili sia sulla scansione sia sulla stabilità di indicizzazione.
Per un modello mentale chiaro del processo (e per capire dove si possono creare colli di bottiglia), questo video ufficiale di Google Search Central è una risorsa utile:
Fattori che influenzano crawlability e profondità di scansione
Quando un sito cresce, non è solo “cosa” è indicizzabile a contare, ma anche “quanto in profondità” Googlebot riesce ad arrivare in modo affidabile. La crawlability dipende da accesso (direttive e status code), ma anche da architettura, performance e coerenenza dei segnali. Lavorare su questi fattori significa rendere più prevedibile la scansione e ridurre sprechi sistemici.
Architettura del sito, link interni e crawl depth (click depth)
La crawl depth (o click depth) è una metrica pratica: quante “mosse” servono, partendo da pagine forti (home, categorie principali), per arrivare a una risorsa. Non esiste una soglia magica valida per tutti, ma in generale le pagine troppo profonde ricevono meno attenzione e vengono aggiornate meno spesso, soprattutto su siti con tante URL concorrenti.
La profondità non dipende solo dal menu: dipende dall’intero sistema di linking (breadcrumb, moduli “prodotti correlati”, pagine hub editoriali, link in template). Su ecommerce, ad esempio, prodotti fuori categoria, o raggiungibili solo tramite ricerca interna, finiscono spesso per essere “deboli” dal punto di vista di crawling e quindi più lenti da consolidare in indice.
Un modo concreto per rendere la depth più “corta” senza stravolgere il sito è creare percorsi di scoperta intenzionali: categorie ben strutturate, sottocategorie sensate, collegamenti tra cluster tematici e pagine “di raccolta” che funzionano da snodo. Poi validi nei log: se dopo il fix vedi crescere le richieste Googlebot sulle directory strategiche, hai migliorato davvero la scansione.
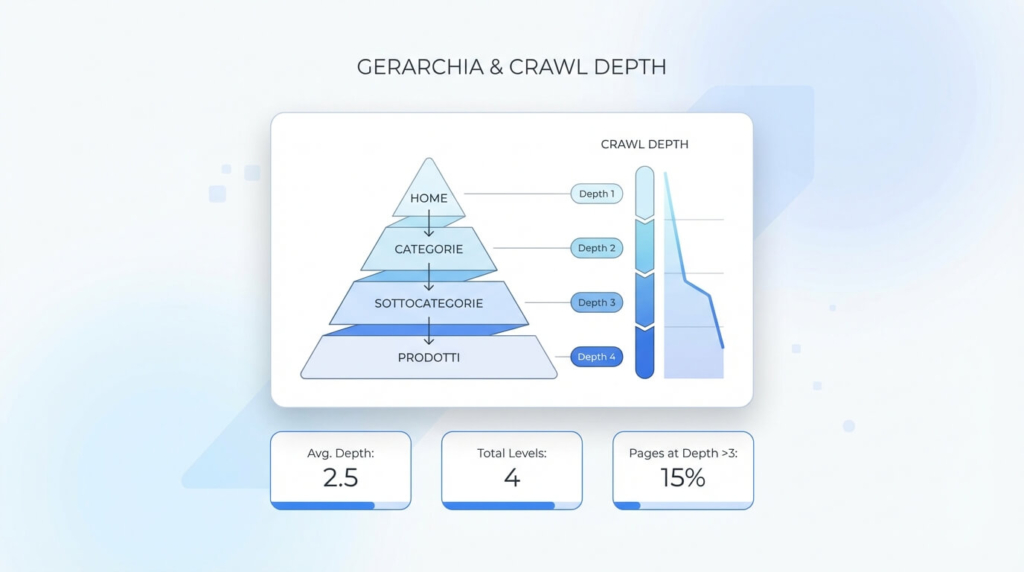
Controlli di accesso e segnali di preferenza: robots, canonical e parametri URL
Nel controllo della scansione, l’obiettivo non è “vietare tutto”, ma rendere chiaro cosa vuoi far trattare come pagina primaria e cosa come variante tecnica. Robots.txt, meta robots, X-Robots-Tag, canonical e gestione dei parametri URL funzionano bene quando non si contraddicono tra loro e quando l’internal linking li supporta.
Un punto spesso sottovalutato è la normalizzazione: se lo stesso contenuto è raggiungibile con e senza slash finale, con maiuscole/minuscole, con parametri di tracking o con querystring inutili, stai aumentando artificialmente la superficie di crawling. La soluzione più pulita è combinare regole di routing (per ridurre le varianti) con canonical coerenti e link interni “puliti” che puntano sempre alla versione preferita.
Nota operativa: Google oggi si affida molto ai segnali on-page e al linking; strumenti specifici per la gestione parametri in Search Console non sono più la leva principale. Per questo, su siti grandi, conviene risolvere a monte (URL generation e linking) invece di sperare in una “scorciatoia” lato motore di ricerca.
Codici di stato HTTP e redirect 301: impatto sul crawling e gestione errori
I codici di stato HTTP sono il linguaggio base tra crawler e server. Non impattano solo l’indicizzazione: impattano direttamente l’efficienza con cui Googlebot riesce a muoversi tra le pagine. Tante risposte 3xx, catene di redirect o errori 5xx significano richieste spese “a vuoto” e spesso una riduzione del crawl rate.
Nella gestione dei redirect, la regola pratica è minimizzare i passaggi: un singolo 301 verso la destinazione finale è molto diverso da una catena A→B→C, soprattutto se moltiplichi il pattern su migliaia di URL. Inoltre, cura i link interni: se continui a linkare URL che poi fanno redirect, stai reintroducendo spreco ogni giorno.
Sul fronte performance, considera anche la qualità delle risposte: un server che gestisce bene cache e risposte condizionali (es. 304 Not Modified, quando appropriato) può migliorare l’efficienza. Ma se dietro ci sono latenza, overload o rate limiting aggressivo, Googlebot si adatta riducendo la scansione: ed è lì che inizi a vedere ritardi su nuove pagine e aggiornamenti.
Errori di scansione più comuni e come risolverli
Gli errori di scansione non sono tutti uguali: alcuni bloccano l’accesso, altri consumano crawl budget, altri ancora creano ambiguità (quindi Google “continua a provare” senza scegliere). La parte utile, in ottica operativa, è collegare ogni errore a una decisione: cosa sistemare subito, cosa gestire con regole e cosa semplicemente accettare perché non impatta KPI e pagine di valore.
Blocchi e direttive: robots.txt, noindex e risorse essenziali non accessibili
Un blocco in robots.txt può essere corretto o disastroso a seconda di cosa stai impedendo di scansionare. Il problema tipico non è bloccare “pagine inutili”, ma bloccare risorse necessarie (CSS/JS) o pagine che dovrebbero consolidarsi in indice. Quando succede, spesso te ne accorgi tardi: la pagina è online, ma Google la interpreta male o non riesce a valutarla come pensi.
Con noindex, invece, l’errore frequente è usarlo in modo incoerente con canonical e linking interno. Se linki fortemente pagine che poi dichiari noindex, stai dicendo a Google “sono importanti” e “non indicizzarle” nello stesso tempo. Su larga scala questo genera spreco e stati ambigui in Search Console.
La soluzione “sostenibile” è una: definire un set di URL primarie (quelle che vuoi davvero indicizzare) e allineare attorno a quel set tre elementi: linking interno, sitemap e direttive (robots/canonical/noindex). Quando questi tre livelli sono coerenti, Googlebot spreca meno e la copertura migliora in modo più stabile.
Errori di risposta: 404, soft 404, 410 e 5xx
Un 404 indica che la risorsa non esiste: è normale che esistano 404, soprattutto su siti con prodotti a rotazione, ma non è normale che siano linkati internamente o che assorbano una quota importante di crawling. Un 410 comunica “rimosso definitivamente” e, in alcuni casi, può accelerare la pulizia di URL ormai obsolete (ad esempio pagine eliminate senza equivalenti). Non è obbligatorio usarlo sempre, ma è una leva utile quando sai che un contenuto non tornerà.
I soft 404 sono più insidiosi: tecnicamente rispondono 200, ma mostrano contenuto vuoto, messaggi generici (“prodotto non disponibile”) o pagine di errore mascherate. Il risultato è doppio: Google perde tempo a scansionarle e spesso le esclude comunque perché le interpreta come non utili. In questi casi, la scelta migliore è rendere lo stato coerente (404/410) o creare un’alternativa reale (categoria, sostituto, contenuto informativo) con segnali chiari.
Sugli errori 5xx non c’è molta filosofia: vanno trattati come incidenti di performance. Se hai manutenzioni programmate, una risposta 503 con header Retry-After è più “onesta” di time-out e pagine instabili. E soprattutto, quando vedi 5xx nei log associati a Googlebot, la priorità è ridurre la probabilità che il crawler venga rallentato a livello di sito intero.
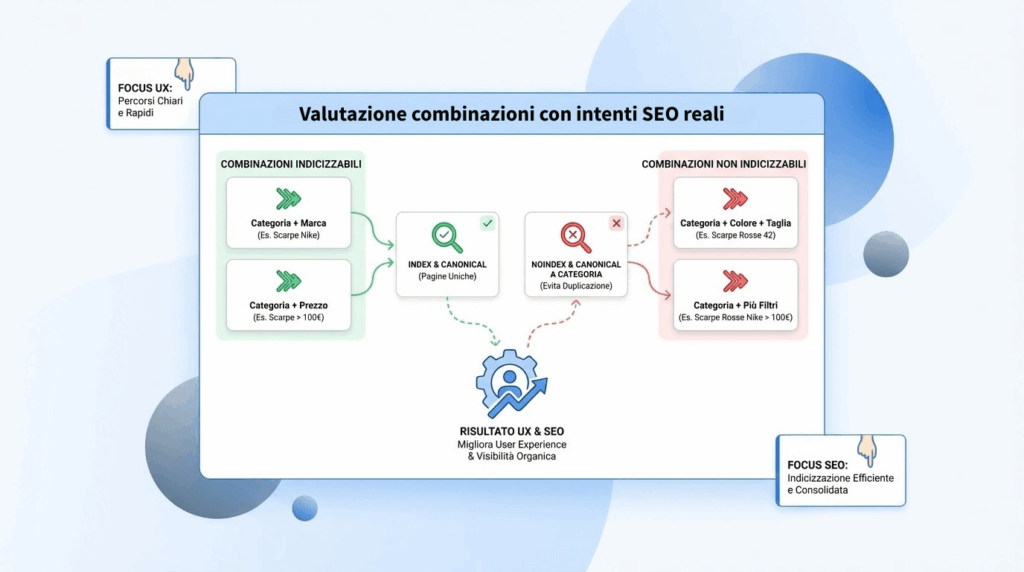
URL problematiche: duplicati, filtri, paginazioni e problemi di rendering
Duplicati e URL “quasi uguali” sono una delle cause più comuni di scansione inefficiente, perché creano un grafo interno enorme che Googlebot prova comunque a esplorare. Filtri e faceted navigation sono spesso la fonte: combinazioni infinite, contenuti simili, canonical incoerenti, paginazioni profonde che moltiplicano ulteriormente le varianti.
Sulla paginazione, la questione è meno “SEO trick” e più accessibilità del contenuto: se hai infinite scroll senza alternative crawlable, o pagine che caricano prodotti solo via JS senza link HTML, stai rendendo la scoperta più fragile. La soluzione pragmatica è garantire percorsi navigabili e linkabili, mantenendo una struttura che non esploda in URL inutili.
Infine, se ci sono problemi di rendering (JS pesante, risorse bloccate, chiamate lente a terze parti), la scansione diventa più costosa e meno prevedibile. In questi casi, ottimizzare il frontend (bundle più leggeri, meno dipendenze, SSR dove serve) e il backend (TTFB, cache, stabilità) non è solo “performance”: è un modo diretto per far lavorare meglio il crawler.
Crawler SEO e audit della scansione: Screaming Frog e pagine orfane
Search Console e log ti dicono cosa succede davvero, ma un crawler SEO ti aiuta a simulare una scansione controllata e a scoprire problemi strutturali prima che diventino “sistema”. È particolarmente utile quando devi capire la crawl depth, mappare redirect e canonical, o individuare pagine importanti non collegate internamente. Se lavori per iterazioni, un crawl periodico è anche un ottimo controllo di qualità post-deploy.
Screaming Frog: come usare un crawler SEO in modo operativo
Con Screaming Frog (spesso chiamato anche “SEO frog crawler”), puoi configurare una scansione molto vicina al comportamento di un bot: scegliere user-agent, gestire robots, seguire redirect, e perfino fare rendering JavaScript per verificare cosa viene realmente visto in fase di rendering. L’aspetto più utile, in ottica crawling, è che ti restituisce pattern: dove stai generando troppe URL, dove ci sono catene 3xx, quali template hanno canonical incoerenti.
Un workflow pragmatico è usare il crawl come “fotografia” della struttura interna e poi incrociare con i log. Se Screaming Frog trova migliaia di URL con parametri linkate internamente, e nei log vedi Googlebot che le scansiona spesso, hai una conferma end-to-end: non è un problema teorico, è un consumo reale di risorse.
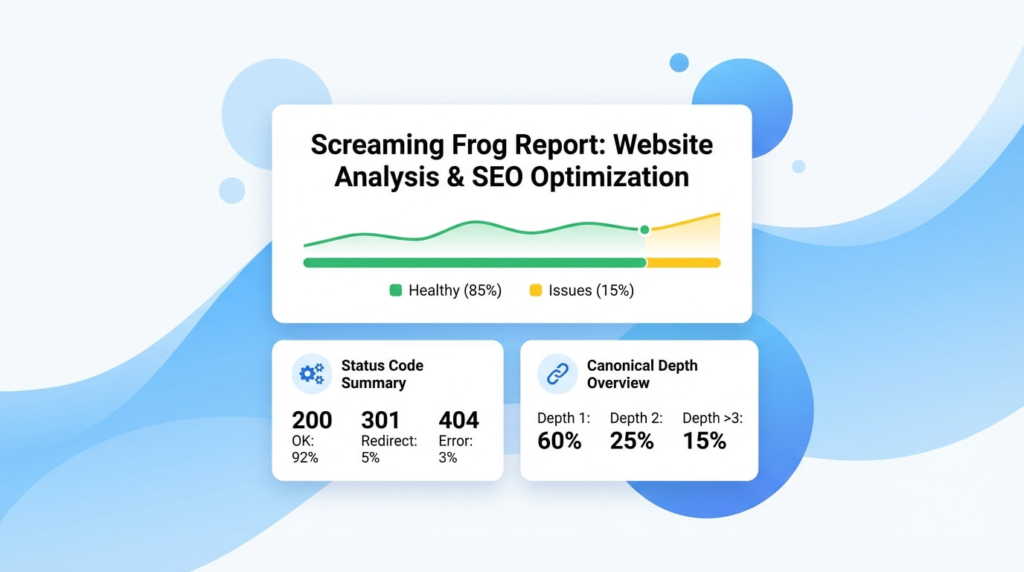
Individuare pagine orfane incrociando crawl, sitemap e dati reali
Le pagine orfane sono URL che esistono (e magari sono in sitemap), ma non ricevono link interni. Su siti grandi è più comune di quanto sembri: prodotti non assegnati a categorie, landing create per campagne poi “dimenticate”, contenuti editoriali non collegati a nessun hub.
Per trovarle in modo affidabile, evita di basarti su una sola fonte. La combinazione che funziona meglio è: crawl del sito (cosa è linkato), sitemap (cosa dichiari importante) e dati reali (log e/o landing page da analytics). Quando una pagina è “in sitemap ma non linkata” e in più non riceve scansioni regolari, quasi sempre stai perdendo opportunità: o la colleghi meglio, o la declassi (noindex) se non ha un ruolo strategico.
Il valore non è “avere zero orfane” (impossibile su progetti grandi), ma assicurarti che non lo siano le pagine che ti aspetti portino traffico organico o conversioni. E qui torna la regola d’oro: la struttura dei link interni è uno dei modi più diretti per orientare il crawler.
Strategie pratiche per migliorare il crawling SEO
Dopo diagnosi e monitoraggio, serve un set di azioni ripetibili che migliorino davvero la scansione: più attenzione alle pagine importanti, meno spreco su varianti e errori, maggiore stabilità nel tempo. Le strategie migliori sono quelle che restano valide anche quando il sito cambia: nuove categorie, nuovi filtri, nuovi contenuti. In altre parole: ottimizzazioni sostenibili, misurabili e facili da mantenere.
Incrementare scoperta e priorità delle pagine importanti con linking interno e sitemap
Se vuoi che Googlebot visiti spesso una pagina, devi renderla facile da trovare e collegarla da URL che Google già scansiona frequentemente. La sitemap XML è un ottimo segnale di discovery, ma il linking interno è ciò che spesso determina la priorità reale: menu, categorie, hub tematici, breadcrumb, moduli “popolari” o “più venduti” possono spostare la distribuzione di scansione in modo netto.
Una strategia che funziona bene su ecommerce è trattare le categorie come “pagine hub” e alimentarle con collegamenti coerenti: categorie principali ben raggiungibili, sottocategorie sensate, pagine editoriali che linkano le categorie strategiche e viceversa. Poi misuri: nei log dovrebbe aumentare la quota di richieste su directory core e ridursi la quota su varianti tecniche.
Quando hai pagine che cambiano spesso (prodotti in stock, pagine news, listini), cura anche i segnali di aggiornamento: lastmod affidabile in sitemap e percorsi interni che le espongano a frequenza di scansione più alta. È un modo concreto per ridurre il ritardo tra aggiornamento e riflesso in SERP.
Ridurre sprechi: parametri, duplicati, thin content e gestione canonical/noindex
Ridurre lo spreco significa restringere la superficie di URL “interessanti” per il bot. In pratica: meno parametri inutili, meno combinazioni di filtri crawlable, meno duplicati e meno pagine a basso valore che continuano a essere scansionate solo perché sono linkate ovunque.
Sul piano operativo, la priorità è mettere ordine sui template che generano thin content o pagine quasi identiche. A volte la soluzione è consolidare (unire contenuti), altre volte è dichiarare in modo coerente che certe varianti non vanno in indice (noindex) o che devono convergere su una canonica. L’importante è evitare segnali “misti”: sitemap che include varianti, link interni che le spingono, canonical che dice il contrario.
Un indicatore semplice per capire se stai andando nella direzione giusta è questo: la quota di scansioni su URL canoniche e indexabili deve crescere nel tempo, mentre la quota su parametri e duplicati deve scendere. Se succede, stai liberando crawl budget dove serve.
Stabilizzare la scansione: performance server, velocità frontend e ottimizzazione redirect
La stabilità del crawling si costruisce con performance backend (server veloce e affidabile) e con un frontend che non renda ogni pagina “costosa” da processare. Googlebot si adatta: se trova lentezza, errori, timeout, riduce la velocità di scansione e diventa più conservativo.
Sul backend, le leve classiche sono caching, CDN, ottimizzazione del TTFB e gestione dei picchi. Sul frontend, invece, ridurre JavaScript superfluo e dipendenze lente migliora sia l’esperienza utente sia la “leggibilità” delle pagine per il motore di ricerca, soprattutto quando entra in gioco il rendering.
Infine, non sottovalutare l’impatto dei redirect: ripulire catene, aggiornare i link interni verso la destinazione finale e ridurre 3xx inutili è uno dei fix più “silenziosi” ma più efficaci per liberare richieste. È una di quelle attività che non fa rumore, ma che si vede chiaramente nei log.
Dai log alle performance: fai scansionare a Google quello che ti fa crescere
Su siti grandi il crawling non è un dettaglio tecnico: è gestione di risorse. Se separi bene crawling, indicizzazione e ranking e lavori in modo data-driven, smetti di inseguire “copertura” generica e inizi a guidare Googlebot verso URL utili, riducendo sprechi su duplicati, parametri e pagine a basso valore. Il punto è sempre lo stesso: meno frizione per il bot (struttura, status code, velocità, rendering), più controllo sul percorso di scansione e più prevedibilità su tempi e impatto.
Se vuoi rendere questa parte davvero operativa, comincia dai dati: incrocia log server e Search Console, definisci pochi KPI di crawling che contano per il business e monitora tutto in una dashboard, così ogni fix si valida con numeri e non con sensazioni. Se ti serve una mano per trasformare questi insight in una roadmap di implementazione sostenibile (con priorità chiare e metriche di successo), contattami.

Mirko Ciesco
Data-Driven Growth Specialist
Aiuto aziende e startup a prendere decisioni migliori per crescere in modo misurabile. Sono specializzato in Web Analytics e performance digitale e lavoro all’intersezione tra dati, strategia e crescita.