




Pubblicato il
SEO Forecasting: trasformare la visibilità organica in previsioni affidabili

Per molte aziende che credono nella crescita, la SEO resta un investimento giusto ma difficile da mettere a budget con la stessa sicurezza di altre leve: si parla di potenziale, raramente di numeri futuri. La seo forecasting nasce per colmare questo vuoto, traducendo ranking, clic e conversioni in scenari previsionali utilizzabili da CFO, marketing e sales senza forzature. Non è una sfera di cristallo: è un metodo per stimare impatto, rischi e tempi con un livello di confidenza esplicito.
Quando la previsione è ben costruita, la conversazione cambia: non più “quanto spendiamo in contenuti?”, ma “quale ritorno ci aspettiamo e quali condizioni devono verificarsi?”.
Indice dei contenuti
Perché prevedere la SEO cambia il modo di investire
La SEO è spesso gestita con logiche di performance a posteriori: si misurano risultati, si interpretano cause, si corregge la rotta. Il forecasting sposta l’attenzione prima dell’investimento, rendendo più chiari i compromessi tra risorse, priorità e tempi. In un contesto competitivo, questa capacità di anticipare è ciò che separa una crescita organica casuale da una crescita deliberata.
Dal traffico ai risultati di business: il punto in cui la SEO diventa pianificabile
Un errore ricorrente è fermarsi alle metriche di superficie: sessioni, impression, posizione media. Sono segnali utili, ma non bastano a giustificare scelte operative e finanziarie, perché non raccontano in modo diretto cosa accade al fatturato o al margine. Il forecasting, invece, obbliga a collegare le variabili SEO (volumi di ricerca, CTR, ranking attesi) a variabili di business come lead, tasso di conversione e valore medio ordine.
Quando questi collegamenti sono tracciati, anche le discussioni interne diventano più concrete: l’espansione su nuove keyword non è pubblicare più contenuti, ma un’ipotesi di copertura della domanda con un effetto stimato su pipeline o vendite. Allo stesso modo, una riduzione di visibilità non è solo un calo di traffico: è un rischio misurabile su obiettivi commerciali. Questo passaggio rende la strategia SEO una leva che può essere confrontata con altre iniziative (adv, partnership, prodotto) su basi più omogenee.
Inoltre, la pianificazione migliora la collaborazione tra team. Marketing può motivare priorità e tempistiche, sales comprende quando aspettarsi un incremento di opportunità, e finance ottiene una logica di proiezione con assunzioni verificabili. La previsione non elimina l’incertezza, ma la rende esplicita e quindi gestibile.
Forecasting vs reporting: smettere di guardare solo nello specchietto retrovisore
Il report SEO racconta ciò che è già successo; il forecasting descrive ciò che potrebbe accadere, se alcune condizioni restano vere o cambiano in un certo modo. Questa differenza è sostanziale perché molte decisioni SEO richiedono anticipazione: assumere risorse, pianificare un restyling, allocare budget per contenuti, scegliere un mercato o una categoria da presidiare. Affidarsi solo al passato porta spesso a reazioni tardive, soprattutto in presenza di update algoritmici o mosse aggressive dei competitor.
Una previsione credibile non promette certezze: costruisce scenari (conservativo, realistico, ambizioso) e li lega a ipotesi dichiarate, come miglioramenti di CTR, crescita di ranking su cluster strategici o aumento della copertura editoriale. In questo modo, se lo scenario non si verifica, la domanda non è “chi ha sbagliato?”, ma “quale ipotesi è cambiata?”: un approccio molto più utile per guidare l’esecuzione.
Un segnale di maturità è separare l’ottimismo dall’evidenza. Se un obiettivo è “+30% traffico organico”, il forecasting chiarisce che cosa deve succedere per renderlo plausibile: quante query devono salire di posizione, quali pagine devono performare, quale capacità di produzione e ottimizzazione serve. Senza questa traduzione operativa, gli obiettivi rischiano di restare aspirazioni e non piani.
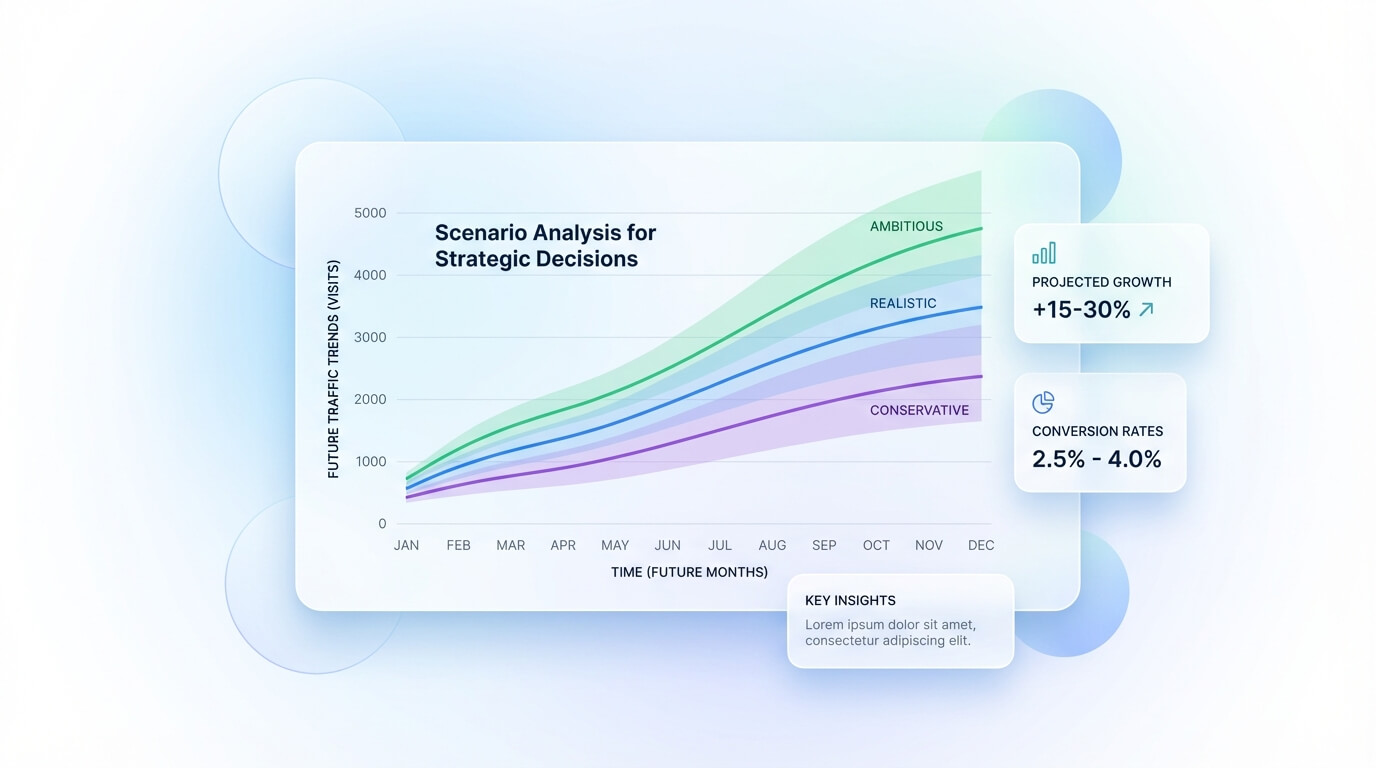
Le condizioni minime per una previsione credibile (e perché contano più degli strumenti)
Il forecasting non dipende da un singolo tool magico: dipende dalla qualità delle basi su cui si costruisce. Senza dati affidabili, anche il modello più sofisticato produce numeri fragili. La prima condizione è una misurazione coerente: tracciamento delle conversioni, definizioni stabili di cosa sia un lead qualificato, segmentazione chiara tra traffico brand e non brand. Se questi elementi cambiano spesso, la previsione diventa instabile e difficile da interpretare.
La seconda condizione è capire la stagionalità e il contesto. Molti settori hanno domanda ciclica: prevedere senza considerare picchi, cali e trend di mercato significa confondere la crescita reale con un semplice effetto calendario. Allo stesso modo, la presenza di campagne offline, variazioni di pricing o cambi di assortimento può alterare conversion rate e valore medio, influenzando l’impatto economico della SEO anche a parità di traffico. Un buon forecasting esplicita queste dipendenze, invece di nasconderle.
Infine, serve una baseline tecnica e contenutistica: se il sito ha problemi di indicizzazione, prestazioni lente o architettura poco leggibile, la previsione deve includere tempi e limiti di recupero. Il punto non è fare numeri da inserire in un report, ma stimare un percorso realistico di miglioramento, distinguendo ciò che è ottimizzazione incrementale da ciò che richiede interventi strutturali. Da qui si può passare a come costruire un modello previsionale pratico e difendibile nelle riunioni decisionali.
Una struttura di forecasting adatta al decision making
Una buona struttura di seo forecasting nasce dall’esigenza di rispondere a domande semplici ma decisive: “quanto possiamo crescere?”, “in quanto tempo?” e “cosa deve succedere perché accada?”. Per farlo, serve un impianto leggibile anche da chi non lavora quotidianamente su SERP e strumenti SEO, ma deve approvare budget e priorità.
Dati e fonti: cosa serve davvero per iniziare senza ipotesi fragili
Come abbiamo detto prima, la qualità del forecast dipende dalla solidità delle fonti. Quando i dati sono frammentati o incoerenti (definizioni di conversione che cambiano, tracciamenti incompleti, segmentazioni assenti), il modello finisce per essere ricco di numeri ma povero di significato. Una base minima, invece, consente di stimare il potenziale e di testare rapidamente la bontà delle assunzioni.
Per costruire un primo modello inattaccabile, le aziende orientate alla crescita si concentrano su poche fonti, ma affidabili e confrontabili nel tempo:
- Google Search Console per query, impression, clic, CTR e pagine di destinazione.
- Web analytics per sessioni, conversioni e segmentazioni (brand/non brand, canali, device).
- CRM o sistema vendite per qualità del lead, ciclo di vendita e valore economico reale.
- Tool SEO per keyword set, ranking storici e confronto competitivo (con prudenza sui volumi).
- Dati di business su stagionalità, margini, disponibilità prodotto/servizio e geografie.
Un aspetto spesso sottovalutato è la coerenza temporale: se il CRM attribuisce ricavi con settimane di ritardo rispetto alla visita organica, il modello deve tenerne conto. Senza questo accorgimento, si rischia di giudicare “sbagliato” un forecast solo perché si sta guardando una finestra temporale non allineata al ciclo reale.
Segmentazione e unità di previsione: perché prendere tutto il sito è quasi sempre una cattiva idea
Fare forecasting sull’intero dominio può essere utile per una vista executive, ma è raro che porti a decisioni operative corrette. La crescita organica, infatti, non è uniforme: cambia per tipologia di intento, per cluster tematici, per mercati e persino per tipologia di pagina (categoria, articolo informativo, prodotto o servizio). Segmentare significa ridurre il rumore e rendere le azioni conseguenti più chiare.
Le unità più pratiche di previsione sono quelle che permettono un legame diretto con le attività: un topic cluster, una directory, una linea di prodotto, un mercato geografico o un insieme di query con intent omogeneo. Se un segmento “transazionale” cresce meno di uno “informazionale”, il forecast aiuta a capire se è un problema di conversione, di posizionamento su query ad alto valore o di offerta. E soprattutto permette di assegnare owner e priorità senza disperdere lo sforzo.
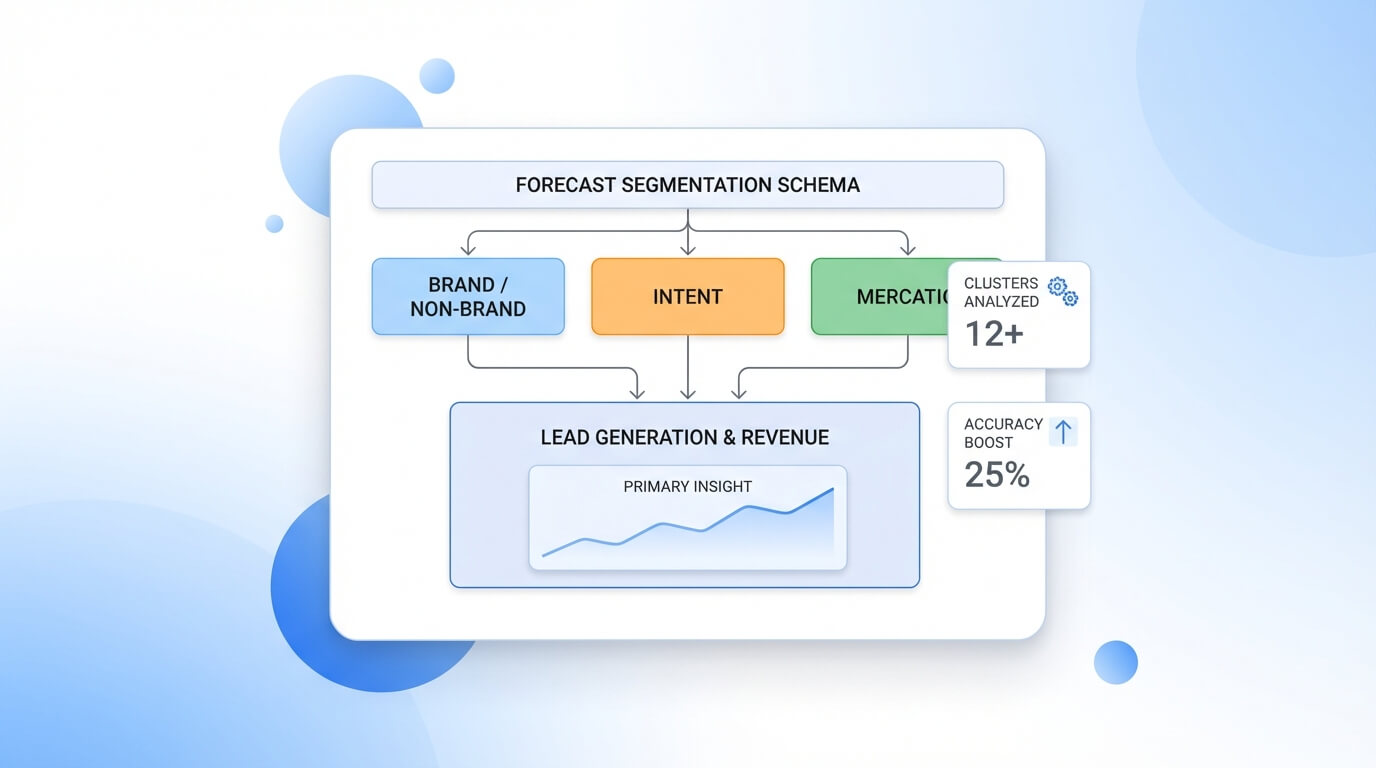
Assunzioni e leve: dove si costruisce (o si rompe) la credibilità del modello
Le assunzioni sono il cuore del forecasting, perché trasformano dati storici in una stima futura. Le aziende che credono nella crescita misurabile non temono le assunzioni: temono quelle implicite. Dichiararle significa poterle discutere, stressare e aggiornare senza riscrivere ogni volta la narrazione dei risultati.
Le leve principali su cui si lavora sono tipicamente tre. La prima è la probabilità di migliorare i ranking su un set di query (in base a gap competitivo, qualità dei contenuti e stato tecnico). La seconda è la variazione del CTR atteso, legata a posizione, snippet e forza del brand in SERP. La terza è la conversione: non solo il tasso, ma anche la qualità, perché un forecast che produce più lead ma peggiori e difficili da qualificare non sostiene davvero la crescita.
La credibilità aumenta quando il modello include vincoli e tempi: capacity di produzione, dipendenze tecniche, velocità di rilascio, necessità di autorevolezza e segnali off-site. In questo modo, la previsione non diventa un numero ottimista, ma una stima condizionata a un piano eseguibile. Da qui, il passo successivo è trasformare la struttura in un processo: aggiornamenti periodici, rivalutazione delle ipotesi iniziali e uso del forecast per decidere roadmap e budget.
Tipologie di SEO forecasting: dal foglio di calcolo al machine learning
Il SEO forecasting non è un’unica tecnica, ma uno spettro di approcci che va da modelli “ragionati” in spreadsheet fino a sistemi statistici e predittivi più sofisticati. La differenza non è solo tecnologica: cambia il livello di assunzioni, il tipo di dati richiesti e la capacità di gestire variabilità (stagioni, update, competitor). In generale, più il modello è avanzato più può essere preciso, ma anche più costoso da implementare e spiegare. La scelta, quindi, dipende da cosa devi decidere e con quale livello di confidenza vuoi sostenere quella decisione. In questa fase preliminare l’obiettivo non è prevedere il futuro, ma creare un range credibile e utile per pianificare.
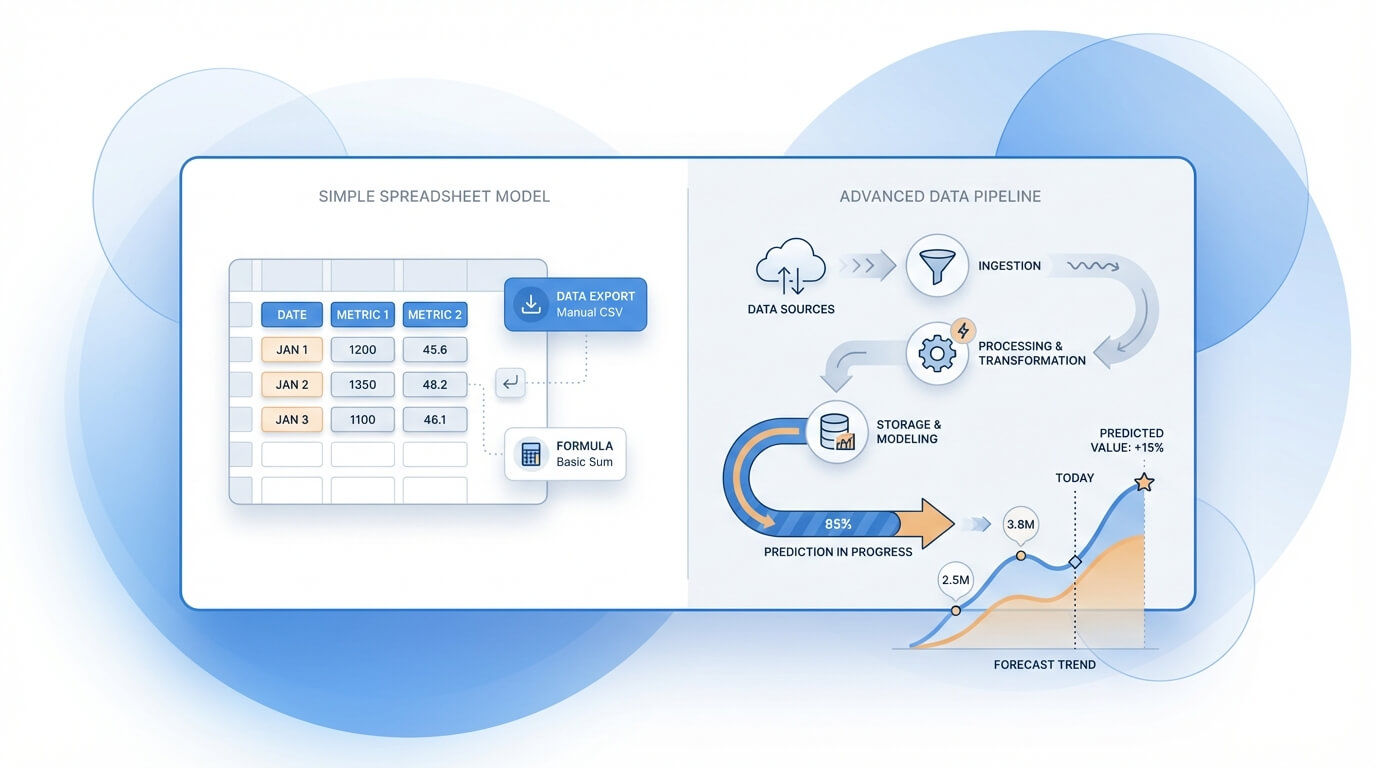
La famiglia “semplice” è quella del foglio di calcolo: si parte da volumi di ricerca, ipotesi di ranking, curve CTR e tassi di conversione per ottenere stime di clic, lead o ricavi. È un approccio molto efficace quando serve allineare rapidamente marketing e finance su ordine di grandezza, priorità e scenari (base / best / worst), mantenendo ogni passaggio leggibile. Il suo valore principale è la trasparenza: tutti vedono cosa muove il risultato e quali assunzioni vanno validate. Funziona bene anche con pochi dati storici, o quando il progetto riguarda nuove keyword/pagine e quindi la serie storica è limitata. Il limite è che spiega bene ciò che ipotizzi, ma fatica a catturare dinamiche complesse come stagionalità fine, volatilità algoritmica o effetti incrociati tra cluster di contenuti.
La famiglia “avanzata” include modelli statistici (time series, regressioni, modelli bayesiani) e machine learning, che apprendono pattern dai dati storici e stimano l’andamento futuro con intervalli di incertezza. Qui entrano in gioco dataset più ricchi: impression e clic da Search Console, performance per template, segnali di brand demand, calendarizzazioni di release, e talvolta variabili esterne. Il vantaggio è la capacità di modellare trend e stagionalità in modo più realistico, distinguendo tra crescita strutturale e rumore, e simulando l’impatto di interventi (nuove sezioni, miglioramenti tecnici, migrazioni). Di contro, richiede qualità e continuità del dato, competenze di analisi e manutenzione del modello: senza governance rischia di diventare una “black box” difficile da difendere internamente. Inoltre, maggiore complessità non garantisce automaticamente migliori decisioni se l’obiettivo è solo stimare ordini di grandezza.
In pratica conviene scegliere in base a obiettivo decisionale, dati disponibili e precisione richiesta: spesso un modello semplice è sufficiente per decidere “dove investire”, mentre uno avanzato serve quando devi decidere “quanto e quando” con maggiore affidabilità e su larga scala. Un criterio utile è pensare in termini di scalabilità: più mercati, categorie e URL devi governare, più ha senso automatizzare e aggiornare la previsione con pipeline dati e modelli robusti. In molti casi l’approccio migliore è ibrido: spreadsheet per costruire il business case e allineare le assunzioni, modello avanzato per raffinare la stima e monitorare lo scostamento nel tempo. In particolare, valuta l’approccio in base a questi segnali:
- Devi produrre rapidamente uno scenario budgetario spiegabile a CFO e stakeholder.
- Hai poca storicità o dati instabili, quindi le assunzioni controllate contano più dell’ottimizzazione matematica.
- Hai almeno 12–24 mesi di dati puliti e vuoi incorporare trend, stagioni e impatti di interventi noti.
- Gestisci molte pagine/mercati e ti serve aggiornare la previsione in modo ricorrente, con controllo degli scostamenti.
Metodo semplice: previsione con dati degli ultimi 12 mesi da Google Search Console
Se ti serve una previsione rapida e incontestabile in riunione, il modo più lineare è partire dai dati reali di Google Search Console. Clic e impressioni degli ultimi 12 mesi contengono già trend, stagionalità e l’effetto combinato di ranking, CTR e domanda: sono quindi una base molto più solida delle sole stime da keyword tool. L’obiettivo non è indovinare il futuro al decimale, ma costruire una baseline che renda chiari ordine di grandezza e range atteso. In pratica: se non cambiasse nulla o tenessimo lo stesso trend di pubblicazione, quale traffico organico potremmo aspettarci nei prossimi mesi? E quanto si discosterebbe lo scenario se investiamo (o se succede un imprevisto)?
Per estrarre i dati:
- Vai in Search Console → “Risultati di ricerca” (report Performance) e imposta l’intervallo “Ultimi 12 mesi”.
- Mantieni “Tipo di ricerca: Web” e, se utile per il budget, applica filtri stabili (Paese, dispositivo) così da evitare mix che cambiano mese su mese.
- Apri la scheda “Date” per avere la serie temporale e poi usa Esporta (Google Sheets/Excel/CSV): l’export giornaliero è il più flessibile perché ti permette di ricostruire i mesi in modo coerente.
Se vuoi una baseline più “pulita”, valuta anche un secondo export filtrando le query brand (o viceversa: solo brand), così da separare la domanda di marca da quella non brand. A questo punto hai una tabella con data, clic e impressioni pronta per l’aggregazione.
Il passaggio successivo è pulizia e aggregazione mensile: in Fogli/Excel crea una colonna “Mese” (es. YYYY-MM) a partire dalla data e costruisci una tabella pivot che sommi clic e impressioni per mese. Prima di usare i numeri per una previsione, vale la pena fare alcuni controlli minimi per evitare che un’anomalia “inquinI” la baseline. In particolare: se l’ultimo mese è incompleto (mese in corso), escludilo o normalizzalo a giorni comparabili; se hai avuto migrazioni, rollout tecnici o penalizzazioni, annotali perché spiegano discontinuità che un modello semplice non può intuire. Infine, calcola anche CTR (clic/impressioni) solo come diagnostica: per la baseline il KPI più stabile resta il totale clic mensile.
- Escludi o normalizza i mesi parziali (mese in corso, periodi con tracking interrotto).
- Separa brand vs non brand se il brand è molto volatile o trainato da campagne/PR.
- Segna eventi straordinari (migrazione, redesign, update importanti, problemi di indicizzazione).
- Controlla outlier evidenti (picchi/crolli isolati) prima di stimare trend e stagionalità.
A questo punto puoi impostare un forecast “quick & dirty” in due componenti: trend e stagionalità. Il metodo più pratico è calcolare la media mobile degli ultimi 3 mesi (livello attuale) e poi applicare dei coefficienti stagionali ricavati dai 12 mesi: per ogni mese, dividi i clic del mese per la media annuale e ottieni un indice (es. agosto 0,85; novembre 1,10). La previsione dei prossimi mesi diventa: “livello attuale × indice del mese”, eventualmente aggiungendo un tasso di crescita lineare (es. +1–3% mese) se il trend degli ultimi 12 mesi è chiaramente positivo. Per rendere la stima più utile a budget, crea tre scenari:
- conservativo (trend piatto),
- centrale (trend storico),
- ambizioso (trend + miglioramento CTR o maggiore copertura).
Ricorda di esplicitare l’assunzione chiave: stai proiettando la performance storica a parità di condizioni, e proprio per questo la baseline è un ottimo punto di partenza per quantificare l’impatto incrementale delle attività SEO.
Esempio in Google Sheets: formule FORECAST() e grafico di trend
Per costruire una previsione leggibile anche da chi non vive di SEO, puoi partire da un dataset minimale in Google Sheets con due colonne: Data (giorno o mese) e Traffico (sessioni organiche o clic). L’obiettivo è stimare il valore atteso nelle prossime settimane/mesi usando una regressione lineare semplice, utile quando vuoi un primo scenario basic senza introdurre troppe variabili. In pratica, trasformi la colonna Data in un asse numerico (un indice 1…N) e applichi funzioni come FORECAST.LINEAR() o TREND() sulla serie storica. Questo approccio non sostituisce modelli più avanzati, ma è perfetto per dare rapidamente una direzione e quantificare un ordine di grandezza.

Imposta il foglio così:
- in A inserisci le date,
- in B il traffico,
- in C un indice progressivo (1 per la prima riga, 2 per la seconda, ecc.)
- in D le date future che vuoi prevedere (o, più semplicemente, continua l’indice).
A quel punto calcoli la previsione in E usando l’indice come “x”, perché le funzioni di forecasting lavorano meglio con una variabile indipendente numerica e ordinata. Ecco due esempi pratici (supponendo storico in C2:C13 e B2:B13, e l’indice futuro in C14): =FORECAST.LINEAR(C14;$B$2:$B$13;$C$2:$C$13) oppure =TREND($B$2:$B$13;$C$2:$C$13;C14).
Se preferisci una versione più “a colonna” per più punti futuri, puoi selezionare E14:E18 e usare TREND con un range di nuovi x: =TREND($B$2:$B$13;$C$2:$C$13;C14:C18).
Per mantenere il file pulito e facile da gestire in futuro, ti conviene standardizzare alcuni passaggi e controlli, così la previsione non diventa una formula magica senza contesto. In particolare:
- Normalizza la granularità (solo giorni o solo mesi) e evita buchi nella serie storica.
- Usa un indice numerico in C invece di affidarti direttamente alle date, per ridurre ambiguità nei calcoli.
- Blinda gli intervalli con i $ (es. $B$2:$B$13) per non trascinare riferimenti errati.
- Se hai stagionalità forte, crea una baseline lineare e poi confrontala con medie mobili o segmentazioni (es. per mese).
Per visualizzare insieme storico e previsione, crea un grafico a linee: seleziona le colonne Data (A) e Traffico (B) + la colonna Previsione (E), poi vai su Inserisci → Grafico e scegli “Grafico a linee”. A livello di lettura manageriale, è utile differenziare le due serie con colori e tratteggi (storico pieno, forecast tratteggiato) e aggiungere una linea verticale nel punto in cui inizia la previsione.
In questo modo ottieni un trend chiaro: lo storico racconta da dove vieni, la linea di forecast quantifica dove potresti arrivare se le condizioni restano simili. E soprattutto hai un output immediatamente spendibile in un documento di planning: una curva con numeri, ipotesi implicite e un metodo replicabile.
Metodo avanzato: SEO forecasting con un modello di machine learning su misura
Quando il forecasting deve diventare davvero il pilota che guida alti budget, il passo successivo rispetto ai modelli standard è costruire un modello su misura allenato sui dati del sito. Qui non si parte da benchmark generici, ma dalle serie storiche reali: impression, clic, ranking (anche per cluster), conversioni e ricavi, con una granularità coerente con la struttura del business. L’obiettivo è stimare non solo dove andremo, ma con quale probabilità e in quali condizioni operative (quali query, quali tipologie di pagina o categorie si dovrebbe andare a lavorare). In pratica, si passa da una proiezione descrittiva a un sistema predittivo che apprende dai pattern interni del progetto. La qualità della previsione dipende più dalla coerenza del dato e dalla corretta modellazione degli eventi che dalla complessità dell’algoritmo.
Il cuore dell’approccio è trasformare gli eventi che muovono davvero la SEO in segnali leggibili dal modello: stagionalità, variazioni di domanda, impatti di update, campagne e cambiamenti sul sito diventano variabili esogene che spiegano gli scostamenti rispetto al normale. Il training include tipicamente periodi pre/post intervento, così da stimare l’effetto medio e i tempi di maturazione (ritardi, plateau, decadimento).
Si costruiscono inoltre feature che rappresentano il contesto: mix di keyword, distribuzione delle posizioni, share di SERP feature, velocità di pubblicazione e refresh dei contenuti. Il risultato è un forecasting che integra causa ed effetto, e non solo l’inerzia del dato. In questa logica, anche un update Google non è rumore: diventa una variabile da codificare e misurare, per quanto con incertezza.
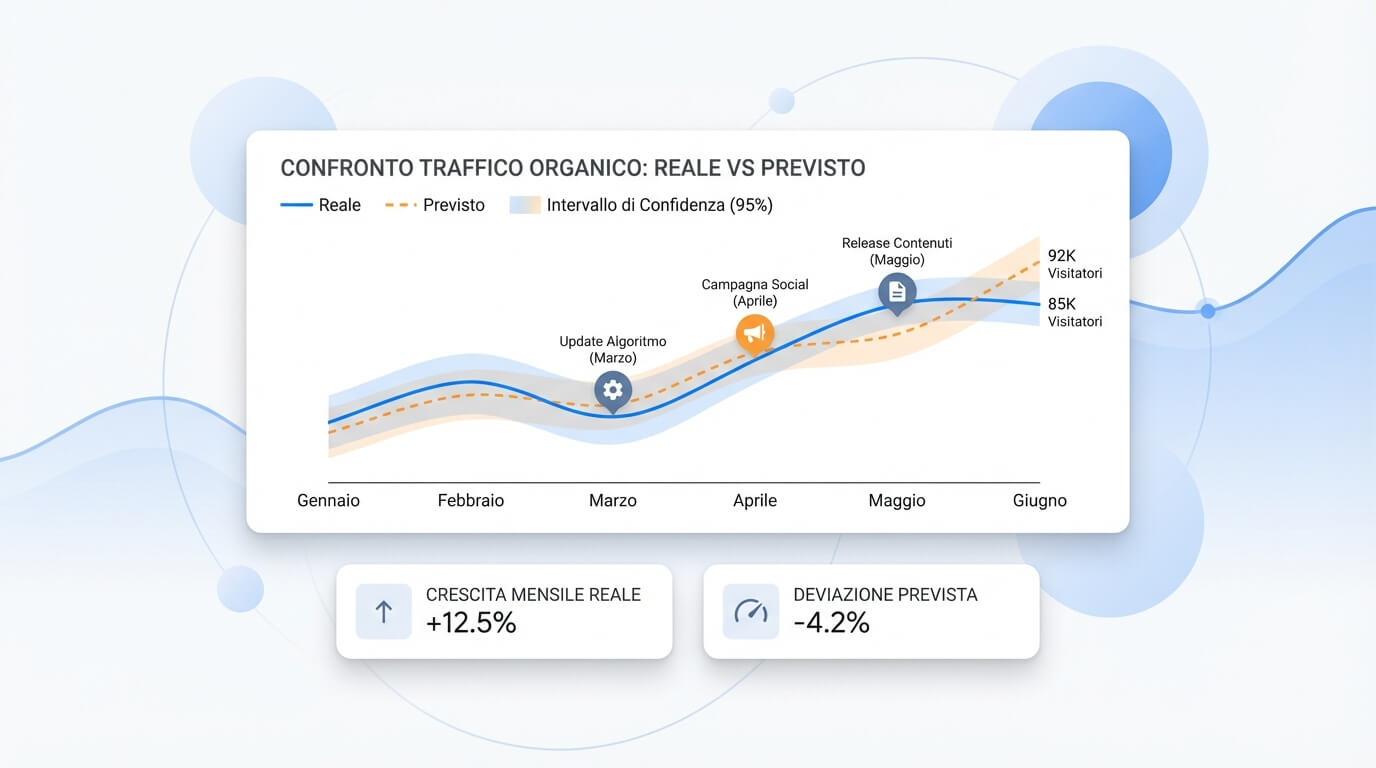
Qui alcuni esempi di feature:
- Storico di performance: impression, clic, CTR, conversioni e ricavi (meglio se per cluster e landing).
- Calendario contenuti: nuove pagine, aggiornamenti, consolidamenti, variazioni di template e internal linking.
- Segnali off-site: acquisizione link, menzioni, variazioni di autorevolezza e distribuzione anchor (quando disponibili).
- Cambiamenti tecnici: migrazioni, release, indicizzazione, Core Web Vitals, log di crawl e errori.
- Eventi esterni: campagne paid/brand, promozioni, PR, stagioni commerciali e annotazioni di update.
La differenza rispetto a un semplice trend è sostanziale: una retta o una media mobile assumono che il futuro replichi il passato, mentre un modello ML prova a stimare come cambiano i risultati al variare delle leve. Questo abilita veri scenari (“se pubblichiamo X contenuti in più”, “se recuperiamo Y pagine in cannibalizzazione”, “se miglioriamo il CTR su top query”) e quantifica l’uplift atteso con tempi realistici.
In più, la previsione può essere fatta a livelli diversi (categoria, cluster, template, singola directory) e poi ricomposta, utile quando serve capire dove allocare risorse. È anche un modo per smascherare false correlazioni: non tutto ciò che cresce insieme spiega la crescita, e il modello costringe a testare la relazione. Il valore pratico è che le priorità SEO diventano ipotesi misurabili, non opinioni.
I benefici principali sono una stima più robusta degli intervalli di confidenza, la capacità di gestire stagioni e shock e un linguaggio più vicino a chi decide budget (rischio, range, sensitività). Detto questo, i limiti vanno esplicitati: se cambiano le regole del gioco (SERP, tracking, mix di query, intent), il modello può degradare e richiede manutenzione. Con dati scarsi o molto sporchi (tracking instabile, attribuzione incerta, eventi non annotati) il rischio di overfitting aumenta e la previsione diventa fragile.
Per questo un approccio serio include backtesting, monitoraggio degli errori previsionali e retraining periodico, oltre a una spiegazione chiara delle variabili che guidano l’output. In altre parole: non sostituisce la strategia, ma la rende più verificabile e più difendibile quando si chiede un investimento.
Variabili e dataset: quali segnali includere nel modello (feature engineering)
La qualità di un forecast dipende più dalle feature che dall’algoritmo: se i segnali non rappresentano davvero la dinamica SEO, anche il modello più avanzato produrrà stime fragili. Il primo passo è scegliere la granularità del dataset (keyword, pagina, directory, cluster tematico) coerente con l’obiettivo: prevedere clic, sessioni o conversioni richiede livelli di dettaglio diversi.
In genere, segmentare per device e paese riduce l’effetto “media” che nasconde comportamenti molto diversi (es. CTR mobile vs desktop). Se il dato è scarso a livello query, una strategia pratica è aggregare per cluster di keyword o per template di pagina (categoria, prodotto, guida), mantenendo però le stesse definizioni nel tempo.
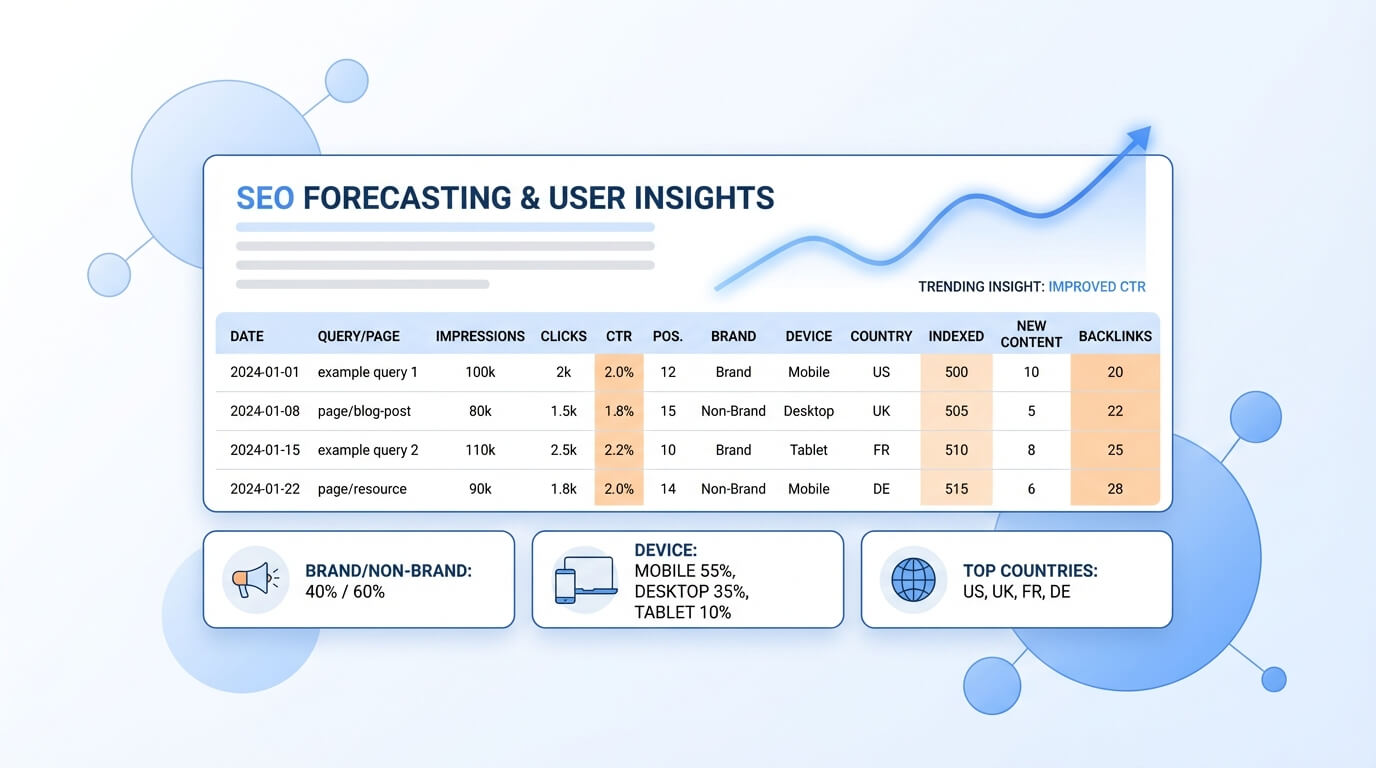
In pratica, un set di feature “tipico” include (e combina) segnali come:
- Impression, clic, CTR, posizione (GSC), anche con lag temporali (t-1, t-4) per catturare inerzia e trend
- Pagine indicizzate e copertura (per directory/template), utili per spiegare limiti di inventory e problemi tecnici
- Pubblicazioni/aggiornamenti (conteggi e recency), per modellare l’impatto di nuovi contenuti e refresh
- Backlink (nuovi referring domains, metriche di qualità), come proxy della spinta off-page
- Segmenti brand vs non-brand, oltre a device/paese, per separare dinamiche e CTR strutturalmente diversi
La preparazione del dataset è ciò che rende queste variabili “addestrabili”: bisogna unire le fonti su chiavi coerenti (data + query/pagina/cluster), gestire i missing (zero reali vs dati mancanti), e normalizzare/trasformare dove serve (CTR come rapporto, impression spesso in log, posizione trattata come variabile continua ma con attenzione agli outlier).
Spesso funziona bene creare feature derivate come medie mobili, variazioni WoW/MoM e indicatori di cambiamento (es. salto di pagine indicizzate o picchi di backlink), perché aiutano il modello a distinguere rumore da segnali persistenti. Infine, documentare le definizioni (es. cosa conta come “pubblicazione”, come si etichetta brand/non-brand) rende il forecast un asset fondamentale.
Output del modello: scenari, intervalli di confidenza e aggiornamento continuo
Un modello di SEO forecasting diventa davvero usabile quando l’output non è un numero unico, ma una forchetta ragionata. Presenta sempre tre scenari:
- baseline (ipotesi più probabile)
- ottimistico (quando le assunzioni migliorano: crescita ranking più rapida, CTR superiore, conversion rate in aumento)
- pessimistico (quando intervengono frizioni: volatilità SERP, stagionalità sfavorevole, ritardi tecnici).
Così il forecast smette di essere una promessa e diventa uno strumento di decisione, perché rende esplicite le condizioni che devono verificarsi. In pratica stai creando un sistema che spiega come cambia l’esito al variare delle leve. Questo è il linguaggio che CFO e marketing possono condividere senza ambiguità: scenario e assunzioni, non speranze.
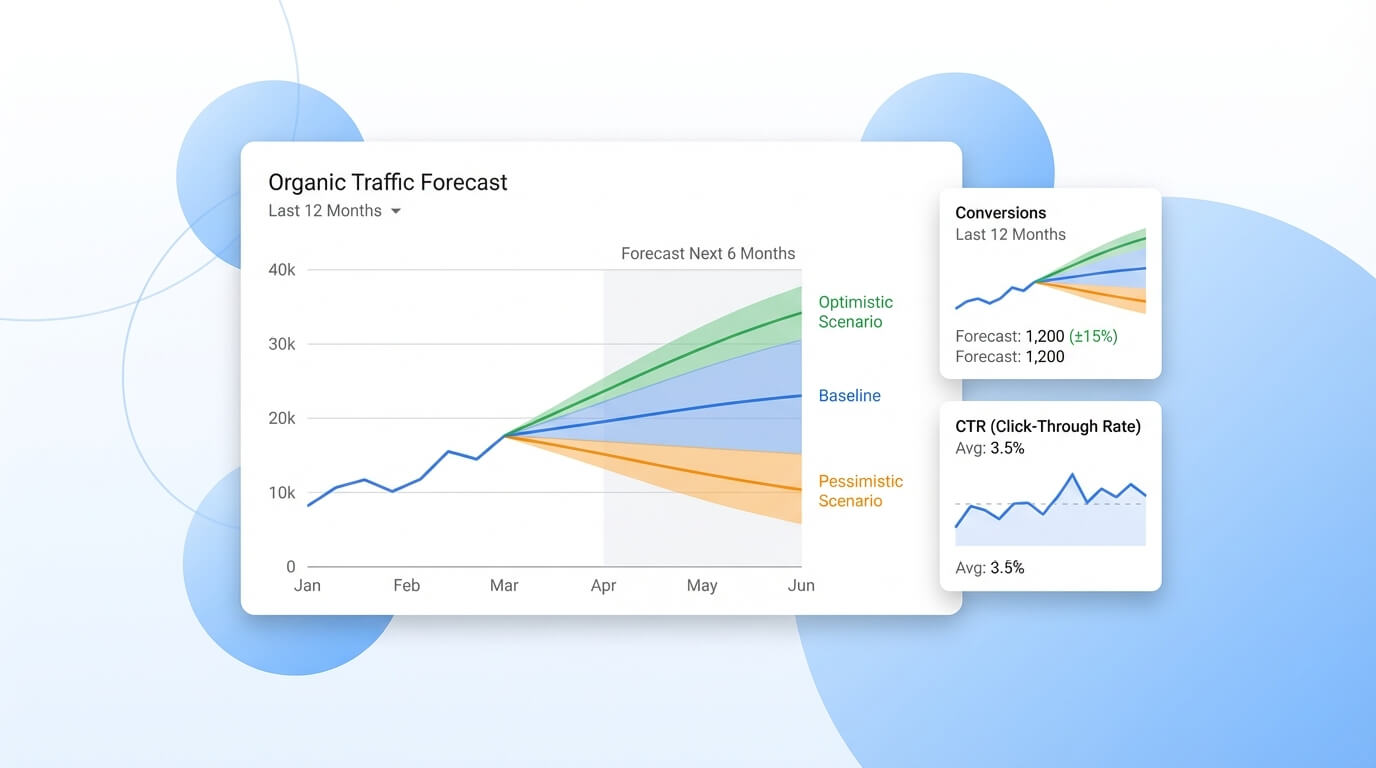
Per comunicare l’incertezza serve una misura chiara, non una nota a margine. Gli intervalli di confidenza (o credibilità, se usi approcci bayesiani) indicano entro quali limiti è ragionevole aspettarsi il risultato, dato lo storico e la variabilità osservata.
Puoi calcolarli in modo pratico con metodi come bootstrap sugli errori storici, regressione con banda di previsione, oppure simulazioni Monte Carlo sulle variabili chiave (CTR, ranking, volumi, conversion rate). L’importante è spiegare cosa rappresentano: non la precisione del modello, ma il range di esiti coerenti con i dati e le assunzioni. Quando mostri una stima, affiancala sempre a una fascia (es. P50/P80) per rendere rischio e probabilità immediatamente leggibili.
Per rendere l’output operativo, struttura il report in modo che il lettore capisca subito “cosa cambia” e “perché”. Alcune buone pratiche che mantengono la previsione trasparente e difendibile:
- Evidenzia il valore centrale (P50) e una fascia prudenziale (P80 o P90) per traffico, lead e revenue.
- Esplicita le assunzioni per scenario (es. tempo di salita keyword, CTR atteso, impatto di interventi tecnici).
- Mostra la decomposizione: variazione dovuta a volumi, ranking, CTR, conversion rate e valore per conversione.
- Indica l’errore storico del modello (MAE/MAPE) e come si è comportato in periodi simili (stagionalità, update).
- Aggiungi un “trigger” decisionale: cosa fare se il risultato si colloca sotto una soglia (piano di mitigazione).
Un forecast non deve essere pubblicato e dimenticato: va monitorato e aggiornato, perché le SERP cambiano e i dati si sporcano. Imposta un ciclo di monitoraggio con alert su drift (scostamenti sistematici tra previsto e osservato) e su rotture di pipeline (tracking, tagging, problemi di analytics).
Quando gli scostamenti superano una soglia concordata, ri-addestra il modello con una finestra temporale aggiornata o con pesi maggiori ai dati recenti, e verifica se nuove variabili (update Google, cambi di layout SERP, nuove feature) stanno alterando CTR e conversioni.
In parallelo, tieni aggiornato dataset e modello per poter spiegare cosa è cambiato e non perdere il controllo. Il risultato è un sistema che non pretende certezze, ma mantiene affidabilità nel tempo, adattandosi al contesto senza riscrivere ogni volta la storia.
Quando la SEO smette di essere una scommessa
La seo forecasting serve a spostare la SEO da ipotesi plausibile a una logica di pianificazione fatta di numeri concreti: non solo misurare ciò che è successo, ma stimare cosa può accadere e con quali condizioni. Collegare volumi di ricerca, CTR e ranking a lead, conversioni e valore economico rende finalmente confrontabili le decisioni SEO con le altre leve di crescita, chiarendo tempi, rischi e priorità con assunzioni esplicite.
Se vuoi che la SEO abbia un posto stabile nel budget e nelle conversazioni con finance e sales, il passo decisivo è costruire scenari previsionali condivisi e aggiornabili, partendo da un perimetro concreto e validando il modello nel tempo. Non promette certezze, ma crea una base solida per decidere meglio: investire dove l’impatto atteso è più alto e intervenire prima che la visibilità organica si trasformi in un problema di business.

Mirko Ciesco
Data-Driven Growth Specialist
Aiuto aziende e startup a prendere decisioni migliori per crescere in modo misurabile. Sono specializzato in Web Analytics e performance digitale e lavoro all’intersezione tra dati, strategia e crescita.